本文转载自: FPGA技术联盟微信公众号
FPGA综合与布线效率研究
如图所示显示了在56核服务器上通过Vivado(8个线程)实现CNN基准测试时的活动CPU内核的数量。整个实现过程大约需要14个小时,平均CPU利用率为2.1核。
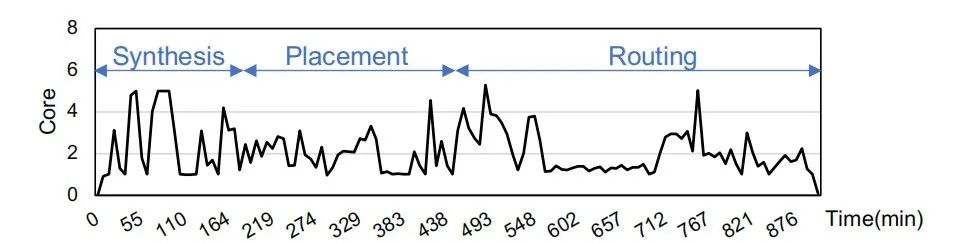
为了继续研究,就增加CPU的线程数目,得到的结果如下:

所以,得出的结论如下:
1、FPGA综合、布线的效率主要却决于CPU单核性能,所以同样的酷睿CPU,同主频下6核的12600K和8核的12700K综合同一个FPGA工程(耗时1小时),基本没什么差异;
2、GPU在综合布线的作用不大,但是GPU对仿真有用,展示波形需要大量的GPU缓存,,所以独立显卡还是很有必要的。
3、内存:越大越好,而且要最新的DDR5;
4、硬盘:NVME 固态硬盘,空间一定要大。
以上观点不是经验,是经过大量实验论证的,请看下面的表:综合、布局布线整个过程中,主要用到2个CPU核,所以,你买个40核的服务器就是交了智商税。
不同CPU下vivado综合对比
参考FPGA工程基本信息:芯片XCZU9CG 1156,时钟120MHz




Vivado在12代酷睿+win11系统下注意事项
12代酷睿最好搭配win11系统,因为12代酷睿采用了大小核架构(性能核P Core和能效核E Core),我们FPGA使用的时候尽量使用P核,win10系统缺乏对核的调度机制,导致性能无法全面发挥。
win11也有一个大问题,目前的调度机制应该是后台应用会交给能效核E,这样问题来了,vivado综合时必须保持软件在前台,才能发挥最高效率;下图未vivado在后台时的情况,主要是4个E核在干活,P核主频也只有4GHz左右;
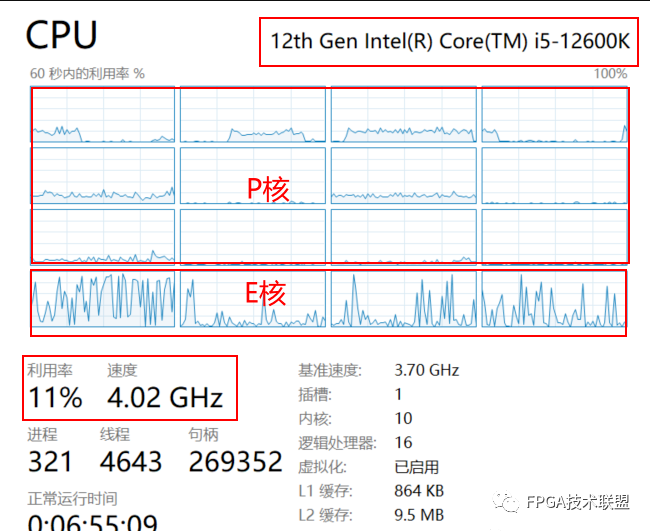
下图是vivado在后台跑出来的时间,原本的1小时变成了1:40

如下图将vivado转到前台后,P核开始干活,E核休息,主频接近5Ghz

此时vivado综合时间恢复到1小时;如果就是要一边看资料一边编译或者同时综合两个工程呢(因为单个工程CPU占用率较低,故两个工程同时综合时相互影响较小),有没有解决办法呢,我尝试了一个办法,确实有效;
所以划重点:
最新的CPU尽管安排上,主频越高,用起来越快,大家还有什么好的技巧,请在下面留言分享!
评论
up
up