本文来源:yportne,转载自: Spinal FPGA微信公众号
不同型号的 FPGA 的硬件资源不同,你所设计的电路结构可能也要相应变化。让我们以一个简单的例子,FIR 滤波器,来看看如何写出能适配不同型号 FPGA 的代码。
本文中的代码以赛灵思的 UltraScale 系列为例。本文的代码不保证逻辑正确性,仅做高频设计方面的研究和示范。
FIR滤波器
先让我们按照赛灵思推荐的写法(ug579)完成一个基础的 FIR 滤波器:

非常整齐的重复的结构,我们只需要完成一个基本单元,然后简单级联就能实现一个任意阶的 FIR 滤波器:
def firStage(input : SInt, H : List[Int], adder : SInt): SInt = {
val nextInput = Delay(input,2)
val thisadder = adder
if(H.length != 0) {
val mult = RegNext(H(0)*nextInput)
val nextAdder = RegNext(mult+thisadder)
val nextH = H.drop(1)
firStage(nextInput,nextH,nextAdder)
}else {
adder
}
}
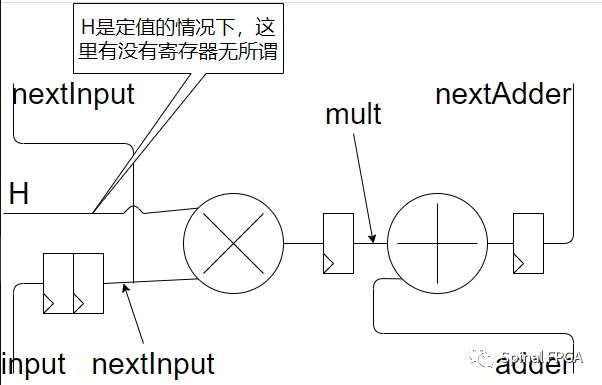
这个代码采用递归的方式实现所需的结构。其顶层如下:
class fir(
Qi : Int,
H : List[Int]
) extends Component {
val io = new Bundle {
val input = in SInt(Qi bits)
val output = out SInt(Qi+log2Up(H.max)+1 bits)
}
def firStage...//这里就是上面的代码
io.output := firStage(io.input,H,S(0))
}
object firtop extends App {
SpinalVerilog(new fir(8,(0 until 72).map(idx => 17).toList))
}
得益于 UltraScale 中同列 dsp 的 cascade 通道,在 ku025 上这个 72 阶的 fir 滤波器能够跑在 400M 以上的时钟频率。看布线后的图可以看到整整齐齐用了一列 dsp。然后问题就来了,如果超过 72 阶会怎么样?修改参数重新生成代码,编译后可以发现,由于 ku025 每列仅有 72 个 dsp,其余的乘法会调用另外一列 dsp,然而缺少了 cascade 通道,跨列的路径会造成极大的时序问题。更麻烦的是,不同型号的 FPGA 每列的 dsp 数量不一样,这又需要针对性的作出参数化的设计。接下来介绍两种解决跨列问题的方案。
打拍
基础的做法是在跨列处额外添加一级寄存器。直接放代码:
import spinal.core._
import spinal.lib._
class fir(
Qi : Int,
H : List[Int],
column : Int = 10000
) extends Component {
val io = new Bundle {
val input = in SInt(Qi bits)
val output = out SInt(Qi+log2Up(H.max)+1 bits)
}
def firStage(input : SInt, H : List[Int], adder : SInt, nowStage : Int = 0, column : Int, startX : Int = 0, startY : Int = 0): SInt = {
val nextInput = Delay(input,if(nowStage%column==0) 3 else 2)
nextInput.setName("input_"+nowStage,true)
val thisadder = if(nowStage%column==0) RegNext(adder) else adder
thisadder.setName("adder_"+nowStage,true)
if(nowStage!=0) {
PrintXDC(s"set_property LOC DSP48E2_X${startX+nowStage/column}Y${startY+nowStage%column-1} [get_cells ${thisadder.getName()}_reg]\n")
}
if(H.length != 0) {
val mult = RegNext(H(0)*nextInput)
val nextAdder = RegNext(mult+thisadder)
val nextH = H.drop(1)
firStage(nextInput,nextH,nextAdder,nowStage+1,column,startX,startY)
}else {
adder
}
}
io.output := firStage(io.input,H,S(0),0,column)
}
object firtop extends App {
SpinalVerilog(new fir(8,(0 until 144).map(idx => 17).toList,48))
PrintXDC("xdc","route.xdc")
}
其中 PrintXDC 的代码如下:
import java.io._
object PrintXDC {
private var xdc : List[String] = List()
def apply(input : String) {
xdc = xdc :+ input
}
def apply(address : String, FileName : String) {
val file = new File(address)
if(!file.exists()) {
file.mkdir()
}
val writer = new PrintWriter(new File(address + System.getProperty("file.separator") + FileName ))
xdc.map(x => writer.write(x))
writer.close
}
def clear() = {xdc = List();}
def get(): String = {
val ret = xdc.reduce(_+_)
ret
}
}
column 参数就是每列使用多少个 dsp。生成 XDC 文件的目的是控制 dsp 的位置,如果没这个需求的话这部分可以不要。上面的代码实现的功能是以 startX 和 startY 两个参数为起始位置向右上放置。这段代码的布线结果如下:
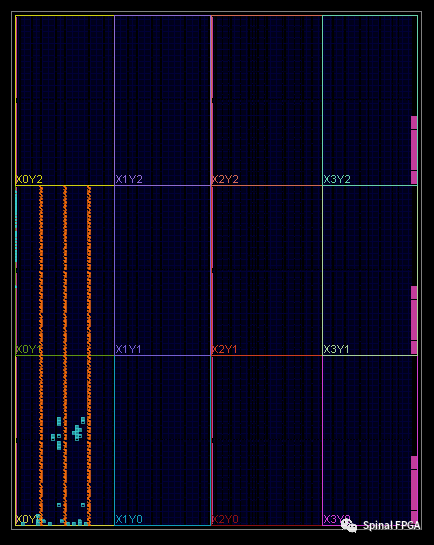
左下角整整齐齐三列 dsp。
分割处理
当一列的 dsp 数量很大时,上一种方式的列间打拍的信号需要跨过很长的距离(从这一列的列尾到下一列的列头),可能会引入时序问题。因此另一种解决方式就是将 FIR 拆分为多个并行处理的块,输入全部从列头进入,最后再从列尾取出相加。结构大概如下图:

代码修改如下:
def firStage(input : SInt, H : List[Int], adder : SInt, nowStage : Int = 0, startX : Int = 0, startY : Int = 0): SInt = {
val nextInput = Delay(input,2)
nextInput.setName("input_"+nowStage,true)
val thisadder = adder
thisadder.setName("adder_"+nowStage+"_X"+startX,true)
if(nowStage != 0) {
PrintXDC(s"set_property LOC DSP48E2_X${startX}Y${startY+nowStage-1} [get_cells ${thisadder.getName()}_reg]\n")
}
if(H.length != 0) {
val mult = RegNext(H(0)*nextInput)
val nextAdder = RegNext(mult+thisadder)
val nextH = H.drop(1)
firStage(nextInput,nextH,nextAdder,nowStage+1,startX,startY)
}else {
adder
}
}
def combineStage(input : SInt, H : List[Int], column : Int, startX : Int = 0, startY : Int = 0): SInt = {
val output = (0 until H.length/column).map{idx =>
firStage(
Delay(input,idx*2*column),
(idx*column until idx*column+column).map(x => H(x)).toList,
S(0),
nowStage = 0,
startX = idx,
startY = 0
)
}
output.reduceBalancedTree((a,b) => RegNext(a+b))
}
io.output := combineStage(io.input,H,column)
cascade 通道简单介
cascade 通道是 dsp 间的特殊连接通道。通常 FPGA 内路径中的时延有相当大部分是 Net Delay,而走特别设计的 cascade 通道能够将 Net Delay 降低到 0.01 左右。上文的代码就是主要利用了 P(输出)到 C(加法输入)的通道。如果使用 ACIN 和 ACOUT 通道,输入可以不打拍,降低整个 FIR 模块的 Latency 至原先的一半,代码仅需一个简单修改:val nextInput = input,顺便,如果发现综合后没有使用 dsp,可以在 mult 的定义后添加一行强制使用 dsp 的综合指令:mult.addAttribute("use_dsp","yes")。更多 cascade 通道的利用可以参考官方文档 ug579,此处就不再赘述。