本文转载自: FPGA打工人微信公众号
注:本文由作者授权转发,如需转载请联系作者本人
数组优化
数组在RTL中映射为memory,一般HLS会自动决定最合适的memory,但也支持通过RESOURCE指令具体的memory实现。
数组分割
HLS的数组分割主要有三种:block,cyclic和complete。
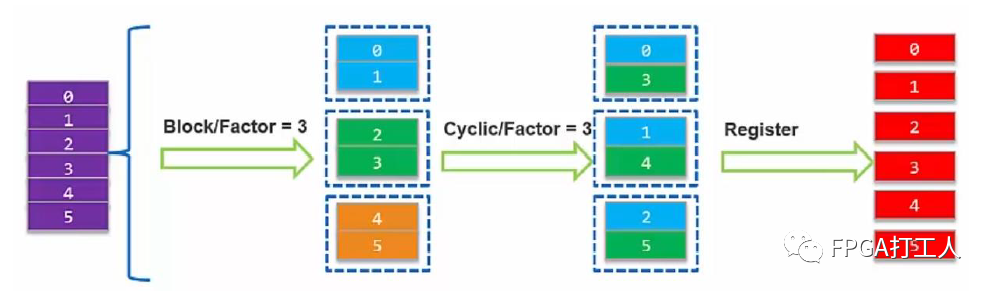
如图所示,block就是以块为单位,一块一块进行填充;cyclic就是在指定块数后,按照一块一元素的方式填充,complete就是通过寄存器来存储每个元素。
具体Directive设置如下所示:

Directive选择ARRAY_PARTITION,factor参数指定分割的块数,dim指定分割的维数,type就是选择哪种分割方式。
数组重组
数组重组通过ARRAY_RESHAPE设置,其只针对同一个数组进行操作。也有block、cyclic和complete三种方式。
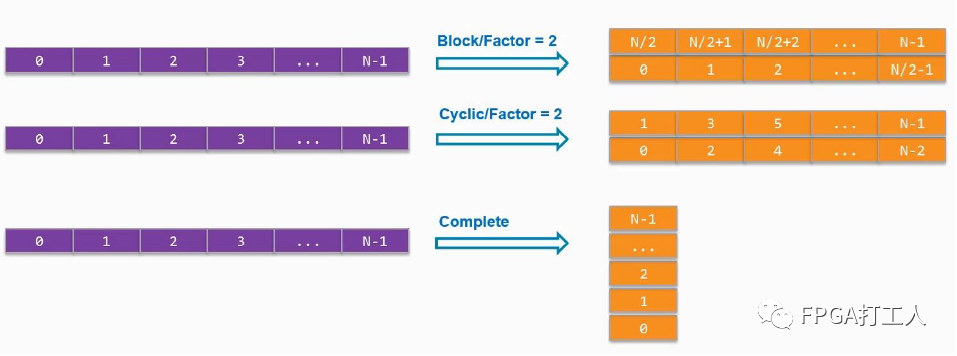
经过block和cyclic方式重组后,数组元素变为一半,位宽变为原来的两倍。经过complete方式重组,元素个数为1,位宽为原来的N倍。
ROM的定义
有时需要定义ROM,在HLS中,最简单的方式就是:const+初始值。当然,也可以采用头文件的方式,如下:
const ap_uint<8> mem[N] = {
#include "des_coef.h"
};
数组初始化
初始化可以直接在前面加关键字static即可。
函数层面的优化
函数层面首先肯定要从code设计和编写中下手,其次,HLS也提供了一些Directive。
INLINE:作用是去除函数的层次化,可以改善资源的消耗。
ALLOCATION:作用是让相同函数被多次调用时可以有多个实例,使之并行执行,用于改善latency并提高吞吐率,但对资源的消耗会增加。
DATAFLOW:在for循环中提到过,这里应用于函数。
总结
实际上,HLS设计时主要关心3个问题:吞吐率、时延、资源。
改善吞吐率的Directive有PIPELINE、ARRAY_PARTITION、UNROLL、DATAFLOW等。
改善时延的Directive有LATENCY、LOOP_MERGE、LOOP_FLATTEN等。
改善资源的Directive有INLINE、ALLOCATE、ARRAY_RESHAPE等。
至于具体的Demo可参考下面的文章,我这边就不做详细的Demo了,其提供了一个fir的具体设计
HLS系列 – High LevelSynthesis(HLS) 从一个最简单的fir滤波器开始
个人的观点看法:
无论是HLS还是Verilog,两者代表了两个“极端”的方向。Verilog可以精准的控制电路实现,但实现起来需要较长的周期,而HLS虽然可快速迭代,但其从软件到硬件翻译无论是面积还是资源均难以控制。HLS的优点是可以更快地实现自己的想法和设计,然后迭代和改进。可以方便地探索设计空间,总之就是极短的开发和验证时间;其缺点是灵活性比较差,明明知道所设计的方案是可行的,但很难将高级语言代码映射为自己想要的电路;出现bug除了可查询高级语言外,很难通过生成的RTL代码进行查询;再怎么优化的 HLS 的硬件,还是没有手写的 Verilog 香啊!