本文为作者对AMD UltraScale FPGA可编程逻辑块的资源和设计方法的学习笔记,主要参考文献为AMD官方文档:UltraScale Architecture Configurable Logic Block User Guide(UG574)。官方文档链接已放在文章最前面,以供大家参考学习和勘误。
由于作者技术和行文水平有限,如有表述不清或者错误的部分,还请批评指正,谢谢!
概述
可编程逻辑块(Configurable Logic Block,简称CLB)是AMD FPGA中用于实现通用组合逻辑和数字逻辑的主要资源。对于UltraScale FPGA,每个CLB中包含一个名为Slice的逻辑资源组合和对应的互联布线资源。Slice包含四种基本的逻辑资源,查找表(Look-Up Table,简称LUT),触发器(Flip-Flop,简称FF),进位链(Carry Logic,简称CARRY)和多路选择器(Multiplexer,简称MUX)。
在UltraScale FPGA中,每个CLB包括一个Slice,每个Slice提供了8个6输入LUT和16个FF,并且这些Slice可以利用内部的布线资源轻松的组合在一起以实现复杂的功能。Slice根据功能的不同被分为SLICEL和SLICEM,这两种Slice在器件中的占比根据型号不同而不同。
SLICEL(L for Logic)主要用于逻辑实现。
SLICEM(M for Memory)除了用于逻辑实现外,也可用于存储。为了实现这个功能,SLICEM的LUT增加了写地址(Write Address,简称WA),写使能(Write Enable, 简称WE)和时钟信号,使这些LUT可以被配置成分布式RAM(Distributed RAM)和移位寄存器(Shift Register Logic,简称SRL)。
总的来说,UltraScale架构的CLB提供了先进,高性能和低功耗的可编程逻辑,包括:
. 真6输入查找表(Real 6-input look-up table (LUT) capability)
. 可选的双5输入查找表(Dual LUT5 (5-input LUT) option)
. 分布式存储和移位寄存器(Distributed memory and shift register logic (SRL) ability)
. 用于算术功能的专用高速进位逻辑(Dedicated high-speed carry logic for arithmetic functions)
. 高效的宽多路选择器(Wide multiplexers for efficient utilization)
. 拥有灵活的控制信号的,可被配置为FF和锁存器的专用存储单元(Dedicated storage elements that can be configured as flip-flops or latches with flexible control signals)
虽然在实际设计中,综合工具会将规范的代码自动映射为FPGA的逻辑资源,但是了解FPGA的架构可以帮助设计人员实现更优的设计。
CLB功能
这部分内容描述CLB各个逻辑单元以及它们组合起来可以实现的功能。
Look Up Table
每个CLB中有8个LUT,每个LUT拥有6个输入和2个输出。因此除了使用一个LUT实现一个6输入的逻辑函数外,也可在1个LUT中可以实现两个5输入或者更少输入的逻辑函数。这样的设计使得2个简单的逻辑函数可以在1个LUT中实现,提升了资源利用率。

根据这样的设计,UltraScale FPGA中的LUT可以实现的功能有以下三种:
. 1个任意6输入布尔函数
. 2个任意5输入布尔函数,只要它们输入相同
. 2个任意3,2,1输入布尔函数
LUT的输出可以根据需要选择, 既可以直接连接Slice的输出端口,也可以连接FF的D端口寄存,也可以送入CARRY或者MUX以实现更复杂的功能。
Flip-Flop
每个CLB中有16个FF,是LUT的2倍(如图所示,1个LUT对应2个FF)。这样的设计旨在充分满足设计者的需要,使其能够更容易地实现流水线结构,从而提高性能。
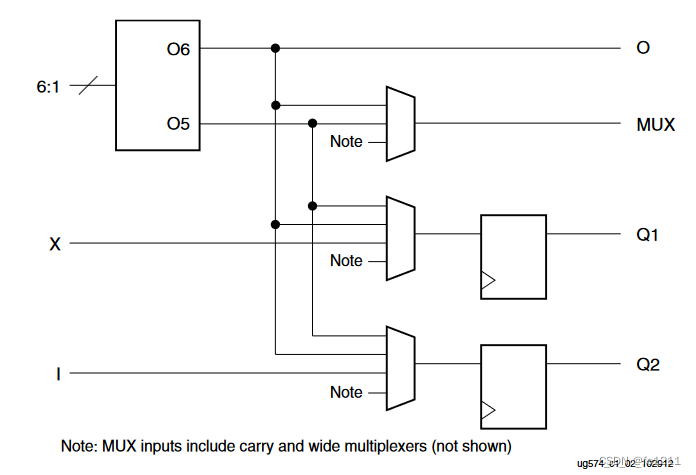
每个CLB拥有2个独立的时钟(Clock,简称CLK)和置位/复位(Set/Reset,简称SR)输入,这两组信号分别控制8个FF。
每个CLB拥有4个独立的时钟使能(Clock Enable,简称CE)输入,可以实现更高的设计效率和功耗表现。
每个CLB的2个SR输入可以被编程为同步或者异步模式,也可被编程为Set或者Reset。
由于CLB的SR输入可以被编程为同步或者异步模式,所以很多文章在对比FPGA同步复位和异步复位时,提出其中某一种需要更多逻辑资源(如在触发器的输入端串联一个与门),对于AMD FPGA是错误的。
事实上,在AMD FPGA中,不论使用同步复位还是异步复位,都不会增加额外的逻辑资源消耗。这点在UltraFast Design Methodology Guide for FPGAs and SoCs(UG949) 中也有提及:
Because all AMD device general-purpose registers can program the set/reset as either asynchronous or synchronous, it might seem like there is no penalty in using asynchronous resets. If a global asynchronous reset is used, it does not increase the control sets. However, the need to route this reset signal to all register elements increases routing complexity.
可见异步复位在AMD FPGA中增加的是布线复杂度,而不是很多人理解的逻辑复杂度。至于在Intel FPGA或者ASIC设计中,引入同步复位是否会增加逻辑资源消耗,作者没有详细的调研过,故无法给出明确的答案,希望大家有知道的可以指出,一起学习。
Mutiplexer
MUX即多路选择器在数字逻辑设计中非常常用,但是利用LUT实现MUX的效率十分低下。
例如,用一个6输入LUT,可以构建一个4选1的MUX。4个输入用于数据输入,2个输入用于选择,列出对应的真值表就得到了该LUT内部应该存储的值。如果要构建8选1的MUX,需要8根数据线,3根选择线共11根线。加起来有2^11种可能,如果用LUT实现,则需要存储2^11个真值,也就是至少要32个6输入LUT。随着N选1中的N增大,需要LUT的数量急剧上升,这样显然是无法接受的。
这里的问题源于,当我们设计MUX时,我们只在乎选择信号的取值,数据信号我们不在乎,连过去就行了。但是基于真值表表示逻辑函数的LUT只能将数据和选择信号的所有可能都存储起来,对于数据信号,相当于实现了一个输出=输入的逻辑函数,本来N根线的事变成了一个2^N bit的RAM。从这里也能看到,FPGA为了实现可编程性,着实牺牲了性能。
考虑到这一现实,AMD在CLB中添加了专用的MUX资源,以提升FPGA在实现MUX时的性能。
AMD FPGA在每个CLB中提供了7个2选1的MUX电路,它们同8个LUT组合可以实现多种不同宽度的MUX:
. 8个4选1的MUX,每个使用0个MUX电路
. 4个8选1的MUX,每个使用1个MUX电路
. 2个16选1的MUX,每个使用3个MUX电路
. 1个32选1的MUX,每个使用7个MUX电路
这样的设计使得原本需要大量LUT的MUX可以在一个CLB中实现,大大提升了效率。这里截取一张16选1的MUX的结构图,以供更好的理解,图中F7MUX_CD,F7MUX_AB和F8MUX_BOT即为专用的2选1的MUX电路。

Carry Logic
CLB内提供了一个专用的快速超前进位逻辑,用来执行快速的加法和减法运算。
Distributed RAM(仅SLICEM支持)
SLICEM中的LUT由于增加了WA,WE和CLK信号,使得其可被配置为分布式RAM。分布式RAM的写操作是同步的,读操作默认是异步的,但是也可以通过将LUT的输出连接到同一SLICEM中的FF上实现同步的读操作。设置读操作为同步可以降低RAM的Tco即clock-to-out延迟,代价为增加一个时钟周期的延迟。
分布式RAM的配置有:
. 单口(Single-Port),同步写和异步读共用一个接口。1个LUT可以被配置成1个64x1或者2个32x1的分布式RAM。
. 双口(Dual-Port),一个接口可以同步写和异步读,另一个接口可异步读。
. 简单双口(Simple Dual-Port),一个接口用于同步写,另一个接口用于异步读。
一个64x1的单口分布式RAM的结构如图所示,读写地址是共用的。

一个64x1的双口分布式RAM的结构如图所示。在写操作时,数据被同时写在两个LUT中。读取的时候通过写地址从第一个LUT中读数据,通过读地址从第二个LUT中读数据,两个操作是独立的。

Shift Register(仅SLICEM支持)
SLICEM中每个LUT可以被配置为32-bit移位寄存器,不需要使用FF。一个CLB中8个LUT连接在一起可以实现一个256-bit的移位寄存器,可将一个信号延迟至多256个时钟周期。多个CLB中的移位寄存器可以连接在一起实现更大的移位寄存器。
除了同步的固定长度读取外,移位寄存器也支持通过LUT的地址线从任意长度处异步读出数据。
设计指南
. CLB的FF只能使用Set或Reset一种,不能在设计中同时使用Set和Reset。
. FF数量充足,考虑利用流水线提升设计性能。
. 在CLB的不同资源共用控制信号,在设计中尽量减少不同控制信号的使用。控制信号包括时钟,时钟使能,Set/Reset和写使能。
. 为了利用LUT实现移位寄存器,避免在移位寄存器中引入复位信号。
. 对于少量的存储需求,考虑使用LUT。
. 标准的数学函数可以利用进位逻辑高效实现。
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/weixin_42434780/article/details/132312508