VCK5000 上的 Aupera ML 推断实现
judy 在 周一, 02/28/2022 - 09:21 提交
该视频介绍了 Aupera 和 Xilinx 在 VCK5000 卡上采用的这种实现方法,以实现完整的视频处理和 ML 推断管道,以及低延迟和高吞吐量的 AI 识别结果。
该视频介绍了 Aupera 和 Xilinx 在 VCK5000 卡上采用的这种实现方法,以实现完整的视频处理和 ML 推断管道,以及低延迟和高吞吐量的 AI 识别结果。

在Vivado里,可以从Block Design导出TCL脚本,保存工程。之后可以从TCL脚本恢复工程。

本指南提供SmartSSD CSD存储加速器模块的安装和功能细节。

VCK5000 开发卡是一款基于 Xilinx Versal 器件的强大加速卡,使用模式与传统 Xilinx Alveo 卡相似。在本视频中,我们将简要介绍在 VCK5000 上的 Vitis 开发步骤。
在我心中,Xilinx是一家完美的公司,技术生态支持实在是做的太好了。Xilinx也知道我们不会用DDR3,所以提供了一个example design给你学习,怎么样?惊不惊喜?意不意外?

本演示视频主要演示运行在 Zynq UltraScale+ MPSoC 上的可编程逻辑的视频处理加速。此外,它还将演示 Xilinx 定向参考设计如何通过在 ZCU102 评估套件中快速启动并运行来缩短客户的设计周期。

本文重点讨论工程师如何在限制质量问题的同时加速FPGA设计,从而缩短产品上市时间。这样,他们可以为客户提供更好的交付时间,从而在竞争中获得优势。
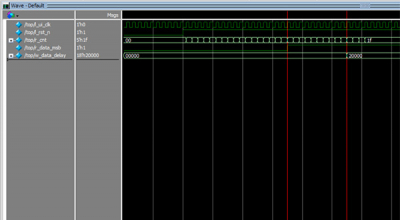
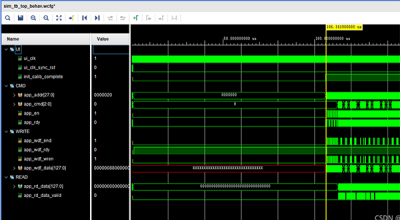
对于xilinx移位寄存器IP的使用而言,其内部为SLR16/SRL32实现。当位深小于32时,其可变延迟是正确的。当大于32,其可变延迟为相同延迟加1。

本文以MRMAC IP为例,并在以太网IP的GT配置那页,选择GTM和156.25MHz时钟。

AMD-赛灵思 AI 团队的论文能在激烈竞争中突出重围,其中一定蕴含着独特的创新与价值。我们与论文第一作者、AMD-赛灵思 AI 团队算法工程师王莉深度对话,为大家带来这份独家的论文解析。