背景:ZynqNet能在xilinx的FPGA上实现deep compression的网络,FPGA端程序运用传入每层数据运算后存在DRAM上。
目的:读懂ZynqNet的FPGA端的代码。
FPGA端代码经过HLS高层次综合为硬件语言实现在FPGA上。为fpga_top.cpp与fpga_top.hpp
程序包括:
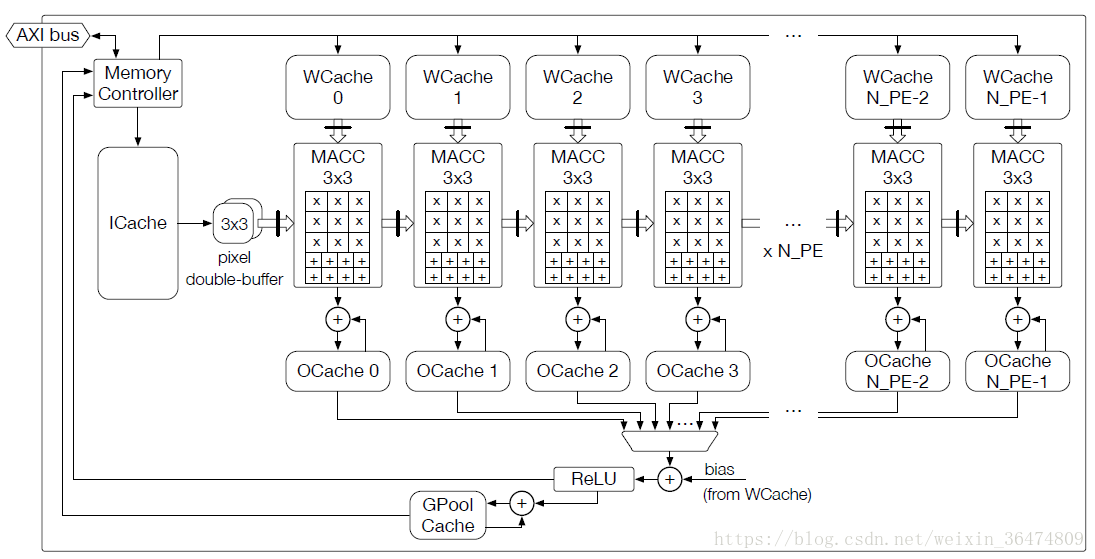
fpga_top
gpool_cache
image_cache
weights_cache
output_cache
processing_element
memory_controller
(数据定义中fpga_top.hpp需要包含了network.hpp与netconfig.hpp)
1. 读取每层信息
// fpga_top
void fpga_top(layer_t layer, data_t *SHARED_DRAM, unsigned int weights_offset,
weightaddr_t num_weights, unsigned int input_offset) {
#pragma HLS INTERFACE m_axi depth = DRAM_DEPTH port = SHARED_DRAM offset = \
slave bundle = memorybus register
#pragma HLS INTERFACE s_axilite port = layer bundle = axilite register
#pragma HLS INTERFACE s_axilite port = num_weights bundle = axilite register
#pragma HLS INTERFACE s_axilite port = weights_offset bundle = axilite register
#pragma HLS INTERFACE s_axilite port = input_offset bundle = axilite register
#pragma HLS INTERFACE s_axilite port = return bundle = axilite register
通过axi-Lite接口读取由CPU传输过来的每层的信息。包括DRAM的地址,层的信息,权重的偏移地址,权重数量,输入的偏移地址。
其中,layer是一个结构体,其中包含了layer的所有信息。在netconfig.hpp中定义。
layer之外的几个变量在cpu_top.cpp中一次性的定义了。只有layer是每层运算都需要传输的信息。
1.1 给所有block设置layer信息
// fpga_top
//setup memory controller
MemoryController::setup(SHARED_DRAM, weights_offset, input_offset);
// Set Layer Configuration
P_layer_setup : {
P_setLayerConfigs : {
ImageCache::setLayerConfig(layer);
WeightsCache::setLayerConfig(layer, num_weights);
MemoryController::setLayerConfig(layer);
ProcessingElement::setLayerConfig(layer);
}
一共设置了五个元素:这五个元素在c语言中为命名空间,并且为全局变量。
MemoryController
ImageCache
WeightsCache
ProcessingElement
1.2 加载权重预加载图像
//fpga_top
// Load Weights from DRAM
WeightsCache::loadFromDRAM(SHARED_DRAM);
// Preload Row 0 + Pixel (1,0)
MemoryController::setPixelLoadRow(0);
ImageCache::preloadRowFromDRAM(SHARED_DRAM);
MemoryController::setPixelLoadRow(1);
ImageCache::preloadPixelFromDRAM(SHARED_DRAM);
2. 运算
hight循环,width循环,对于每一个pixel位置
2.1 image piexl to ICache
// fpga_top for height for width
// Load Next Pixel (automatically checks #pixels left)
ImageCache::preloadPixelFromDRAM(SHARED_DRAM);
2.2 stride=2时
// per pixel
// Stride-2 Skipping
if (layer.stride == 2 & (x % 2 | y % 2)) {
LOG("stride-2, skipping pixel\n");
LOG_LEVEL_DECR;
continue;
}
stride为2时,跳过不需要卷积的像素点。(continue为结束单次循环)
2.3 for channel in
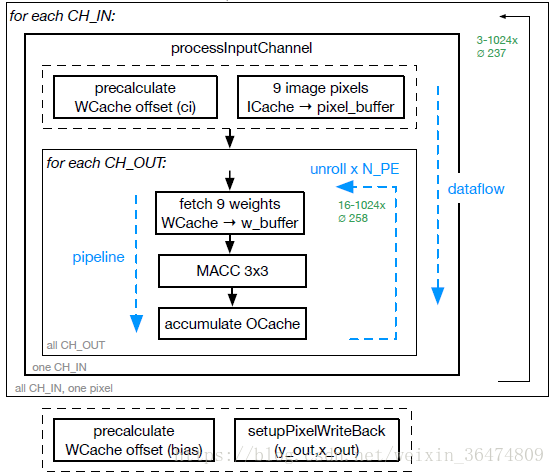
2.3.1 processInputChannel
// fpga top per pixel for channels in
ProcessingElement::processInputChannel(y, x, ci, layer.channels_out);
// processing_element.cpp
void ProcessingElement::processInputChannel(const coordinate_t y,
const coordinate_t x,
const channel_t ci_in,
const channel_t ch_out) {
#pragma HLS inline off
#pragma HLS FUNCTION_INSTANTIATE variable = ci_in
#pragma HLS dataflow
channel_t ci = ci_in;
weightaddr_t ci_offset;
data_t pixel_buffer[9];
#pragma HLS ARRAY_PARTITION variable = pixel_buffer complete dim = 0
// Preload Image Pixel Buffer (fetch pixels around (y,x,ci))
preloadPixelsAndPrecalcCIoffset(y, x, ci, ch_out, ci_offset, pixel_buffer);
// MACC All Output Channels
processAllCHout(ch_out, ci, ci_offset, pixel_buffer);
}
运用ProcessingElement::processInputChannel函数对所有输入piexl进行MACC运算,然后输出存到OCache之中。
2.3.2 setPixelWriteBack
// Calculate Output Pixel Coordinates
dimension_t y_out = (layer.stride == 2) ? (int)y / 2 : (int)y;
dimension_t x_out = (layer.stride == 2) ? (int)x / 2 : (int)x;
MemoryController::setupPixelWriteback(y_out, x_out);
// Select bias coefficients
// WCache.setInputChannel(layer.channels_in, layer.channels_out);
weightaddr_t ci_offset =
WeightsCache::precalcInputOffset(layer.channels_in);
2.3 for channels out

2.3.1 post process
// per pixel for channels out
// Postprocess
data_t processed = ProcessingElement::postprocess(co, ci_offset);
// Writeback to DRAM
MemoryController::writeBackOutputChannel(SHARED_DRAM, co, processed);
进行后续处理,加偏置项和ReLU激活。并且将结果写回DRAM
2.3.2 gloabl_pool
// Accumulate for Global Pooling (if enabled)
if (layer.global_pool == true) {
if (x_out == 0 && y_out == 0)
GPoolCache::setChannel(co, processed);
else
GPoolCache::accumulateChannel(co, processed);
}
如果有global_pool的话进行globla_pool
---------------------
作者:邢翔瑞
来源:CSDN
原文:https://blog.csdn.net/weixin_36474809/article/details/82683399