作者: 饿狼传说,文章来源: FPGA的现今未微信公众号
注:本文由作者授权转发,如需转载请联系作者本人
最近在xilinx Virtex® UltraScale+™系列的芯片上使用了HBM,发现相比传统的DDR,还是有很多不错的地方,这里对HBM的使用做一个简单的总结。
首先对HBM需要有一个整体的了解,建议先看看xilinx的PG276这个文档。如果不想看,可以看看这里对HBM的架构做的一个简单总结。
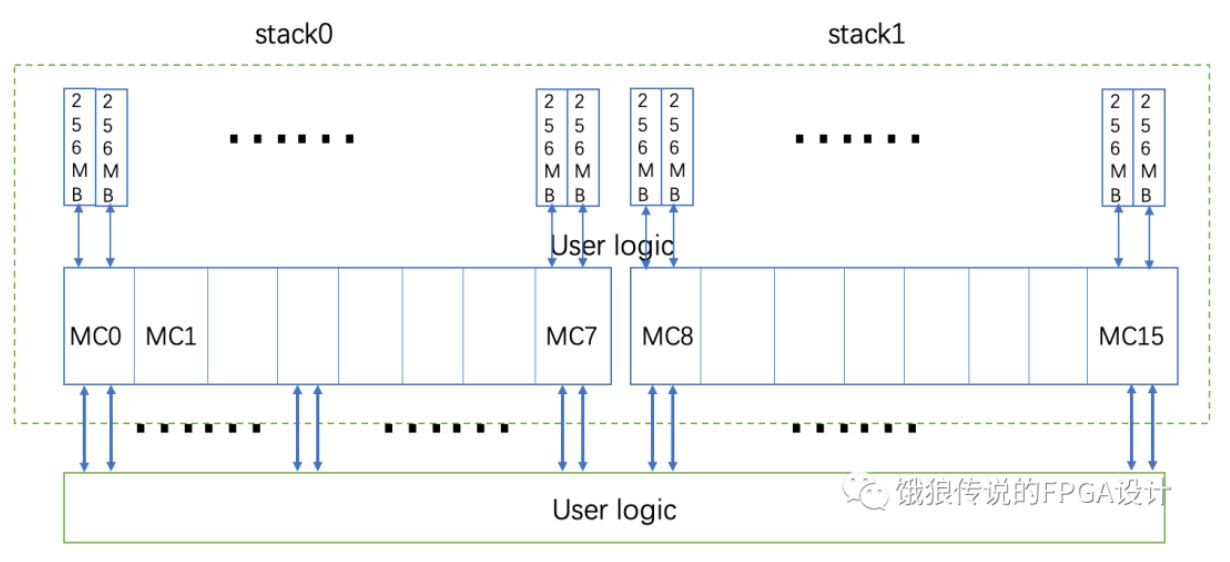
(1)、HBM在架构上分成2个stack,每个stack有8个控制器,一共16个控制器。每个控制器又有2个伪随机通道,即2个aximm接口,即整个HBM提供最多32个aximm接口。
(2)、容量上,我们以8GB空间的HBM为例,一个stack是4GB空间,每个控制器对应4GB/8 = 512MB空间,每个伪随机通道对应256MB空间。用户可以以256MB为单位组合成用户想要的空间。
(3)、访问方式上,有2种方式,global模式和非global模式,在非global模式下,每个用户通过伪随机通道只能访问对应的256MB空间;global模式下,每个伪随机通道可以访问整个HBM空间。
(4)、性能上,每个用户接口(伪随机通道)的数据位宽为256bit,最高工作频率为450M,所以每个用户接口的最大性能为:256bit*450M = 14400MB/s。在global模式下,通过一个伪随机通道,访问其他的控制器对应的存储空间,性能会降低,具体见PG276上的说明。
前面介绍了基本概念,那具体如何使用呢?这里通过一个例子说明,假设需要3个存储空间,容量大小分别为2GB、2GB、1GB,每个存储空间需要提供2个用户接口,即axim接口。那如何配置我们的HBM呢?这里有2种方案:
方案一:2GB的空间,使用4个控制器,但是只例化2个axim接口,同理,1GB的空间,只用2个控制器,也只例化2个axim接口,HBM采用global模式,如下图所示:

MC0到MC3、MC4到MC7分别组成2个2GB的存储空间,MC8到MC9组成1GB的存储空间,每个存储空间只使用2个axim接口,这种方案的优点就是接口简单,在生成HBM core的时候直接配置就好,但是也有一个缺点,就是当某个接口访问其他的MC时,性能会受到影响。
方案二:MC的配置和方案一相同,但是HBM采用的是非global模式,即每个伪随机通道只能访问256MB的存储空间,然后通过一个interconnect来做路由桥接,如下图所示:
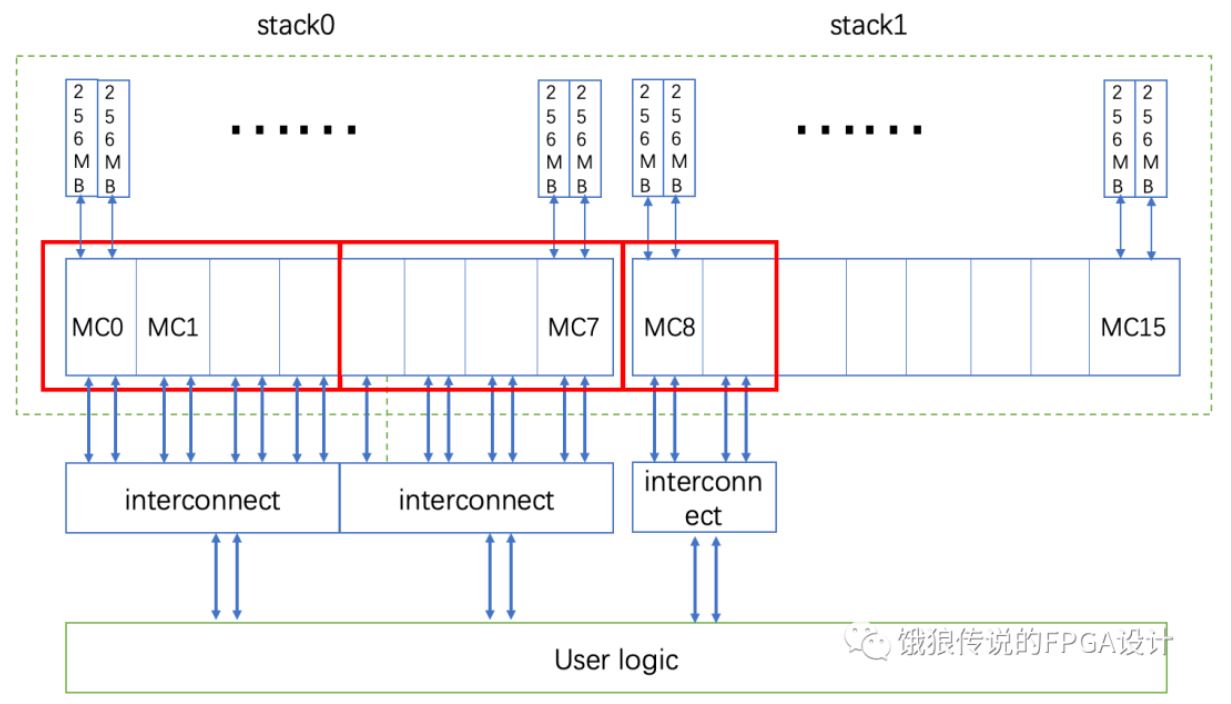
每个存储空间,使用一个interconnect,以2GB空间为例,它对应的interconnect是2个slave端口和用户逻辑相连,8个master端口和HBM相连。通过interconnect实现数据路由。这种方案的好处就是HBM的性能比较高,缺点就是多加了一级interconnect,无论在资源还是延时上都有影响,尤其是延时。