小小Alveo U50 加速器卡大放异彩
judy 在 周一, 08/19/2019 - 16:59 提交
对赛灵思而言,上星期是激动人心的一个星期。业界首款半高半长、可支持 PCIe Gen 4 的自适应加速器卡Alveo U50 正式发布。长约7英寸,宽约2英寸,Alveo U50是小型封装的一大突破。该卡集成 HBM2 高带宽存储器、100Gbps 网络连接和赛灵思 UltraScale+ FPGA 架构
对赛灵思而言,上星期是激动人心的一个星期。业界首款半高半长、可支持 PCIe Gen 4 的自适应加速器卡Alveo U50 正式发布。长约7英寸,宽约2英寸,Alveo U50是小型封装的一大突破。该卡集成 HBM2 高带宽存储器、100Gbps 网络连接和赛灵思 UltraScale+ FPGA 架构

2019Xilinx暑期学校全记录

在这篇文章里你可以了解到广告推荐算法Wide and deep模型的相关知识和搭建方法,还能了解到模型优化和评估的方式。我还为你准备了将模型部署到FPGA上做硬件加速的方法,希望对你有帮助

本文介绍两种LVDS数传接口:GMSL和FPD Link,这两种接口在汽车视频传输方面的应用是比较广泛的,尤其是Camera和处理器之间的链路,通过STP或者同轴电缆能使整个链路达到15m。
1、FPD Link

面向 Zynq UltraScale+ MPSoC 器件的 Xilinx® LogiCORE™ IP H.264/H.265 视频编解码器单元 (VCU) 内核能够以 60Hz 的像素对分辨率高达 4k 的视频进行同步压缩和解压缩。分辨率高出 4K 时,支持较低的帧速率。

卷积占据了CNN网络中绝大部分运算,进行乘法运算通常都是使用FPGA中的DSP,这样算力就受到了器件中DSP资源的限制。比如在zynq7000器件中,DSP资源就较少,神经网络的性能就无法得到提升。利用xilinx器件中LUT的结构特征,设计出的乘法器不但能灵活适应数据位宽,而且能最大限度降低LUT资源使用
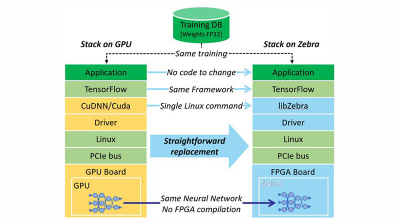
Zebra 可消除深度学习推断中具有挑战性的编程及 FPGA 任务。Zebra 可轻松部署和适应广泛的神经网络及框架。

AXI GPIO模块将PL端连接的GPIO信号通过AXI接口与PS模块连接,PS通过AXI接口的地址映射对PL端的GPIO信号进行读写等控制。与EMIO可以实现相同的功能,区别主要在于EMIO对于少数GPIO接口进行单独的控制,而AXI GPIO可以对多个GPIO接口合并成的总线进行整体读写控制。
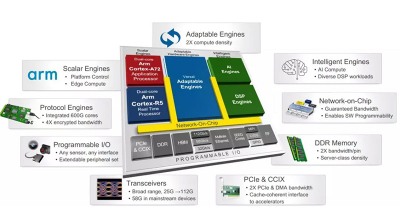
ACAP是Xilinx推出的一种革命性异构计算架构,计划在今年10月份推出。它将标量计算,可编程逻辑还有矢量计算结合在一起,充分利用各自的优势,不仅仅增强了针对各种机器学习算法的适用性,也提高了计算密度和存储带宽。其中AI engine和NoC是新颖的设计,FPGA和CPU的结合早在zynq系列中已经应用

上文介绍了用TCP发送“Hello World”的实例,工作在client模式下。本文实现同样的功能,但让TCP工作在server模式下。把开发板当作服务器,远程主机为客服端访问服务器,实现被动连接。TCP client和TCP server在lwIP中的连接流程和区别可参考本系列前面与lwIP相关的文章