版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/v13910/article/details/82023580
1.DCT原理
DCT经常用来对信号进行有损数据压缩,这是由于DCT具有很强的能量集中性,大部分自然信号的能量主要集中在DCT变换后的低频部分,具体的DCT公式这里就不多推导了(笔者也不是很懂)。二维DCT变换是在一维DCT变换的基础上,再进行一次DCT变换,二维DCT变换方法主要由三个步骤组成(信号矩阵8*8):
(1)对行进行一维DCT得到A。
(2)对A进行行列转置,然后对行进行一维DCT,得到B。
(3)对B进行转置。
2.HLS实现DCT
添加源文件(source):
一维DCT:
void dct_1d(dct_data_t src[DCT_SIZE], dct_data_t dst[DCT_SIZE])
{
unsigned int k, n;
int tmp;
const dct_data_t dct_coeff_table[DCT_SIZE][DCT_SIZE] = {
#include "dct_coeff_table.txt"
};
DCT_Outer_Loop:
for (k = 0; k < DCT_SIZE; k++) {
DCT_Inner_Loop:
for(n = 0, tmp = 0; n < DCT_SIZE; n++) {
int coeff = (int)dct_coeff_table[k][n];
tmp += src[n] * coeff;
}
dst[k] = DESCALE(tmp, CONST_BITS);
}
}定义dct_coeff_table为系数矩阵(一堆cosin)。
二维DCT:
void dct_2d(dct_data_t in_block[DCT_SIZE][DCT_SIZE],
dct_data_t out_block[DCT_SIZE][DCT_SIZE])
{
dct_data_t row_outbuf[DCT_SIZE][DCT_SIZE];
dct_data_t col_outbuf[DCT_SIZE][DCT_SIZE], col_inbuf[DCT_SIZE][DCT_SIZE];
unsigned i, j;
// DCT rows
Row_DCT_Loop:
for(i = 0; i < DCT_SIZE; i++) {
dct_1d(in_block[i], row_outbuf[i]);
}
// Transpose data in order to re-use 1D DCT code
Xpose_Row_Outer_Loop:
for (j = 0; j < DCT_SIZE; j++)
Xpose_Row_Inner_Loop:
for(i = 0; i < DCT_SIZE; i++)
col_inbuf[j][i] = row_outbuf[i][j];
// DCT columns
Col_DCT_Loop:
for (i = 0; i < DCT_SIZE; i++) {
dct_1d(col_inbuf[i], col_outbuf[i]);
}
// Transpose data back into natural order
Xpose_Col_Outer_Loop:
for (j = 0; j < DCT_SIZE; j++)
Xpose_Col_Inner_Loop:
for(i = 0; i < DCT_SIZE; i++)
out_block[j][i] = col_outbuf[i][j];
}输入缓存buffer:
void read_data(short input[N], short buf[DCT_SIZE][DCT_SIZE])
{
int r, c;
RD_Loop_Row:
for (r = 0; r < DCT_SIZE; r++) {
RD_Loop_Col:
for (c = 0; c< DCT_SIZE; c++)
buf[r][c] = input[r * DCT_SIZE + c];
}
}输出缓存buffer:
void write_data(short buf[DCT_SIZE][DCT_SIZE], short output[N])
{
int r, c;
WR_Loop_Row:
for (r = 0; r < DCT_SIZE; r++) {
WR_Loop_Col:
for (c = 0; c< DCT_SIZE; c++)
output[r * DCT_SIZE + c] = buf[r][c];
}
}dct:
void dct(short input[N], short output[N])
{
short buf_2d_in[DCT_SIZE][DCT_SIZE];
short buf_2d_out[DCT_SIZE][DCT_SIZE];
// Read input data. Fill the internal buffer.
read_data(input, buf_2d_in);
dct_2d(buf_2d_in, buf_2d_out);
// Write out the results.
write_data(buf_2d_out, output);
}添加头文件(File—>new File):
#ifndef __DCT_H__ #define __DCT_H__ #define DW 16 #define N 1024/DW #define NUM_TRANS 16 typedef short dct_data_t; #define DCT_SIZE 8 /* defines the input matrix as 8x8 */ #define CONST_BITS 13 #define DESCALE(x,n) (((x) + (1 << ((n)-1))) >> n) void dct(short input[N], short output[N]); #endif // __DCT_H__ not defined
至此,所有的源文件和头文件全部生成。对源文件进行综合(Synthesis):
时序:
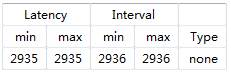
资源消耗:

接下来就是写testbench,测试这个RTL模块功能到底正确不正确:
testbench:
int main() {
short a[N], b[N], b_expected[N];
int retval = 0, i;
FILE *fp;
fp=fopen("in.dat","r");
for (i=0; i<N; i++){
int tmp;
fscanf(fp, "%d", &tmp);
a[i] = tmp;
}
fclose(fp);
fp=fopen("out.golden.dat","r");
for (i=0; i<N; i++){
int tmp;
fscanf(fp, "%d", &tmp);
b_expected[i] = tmp;
}
fclose(fp);
dct(a, b);
for (i = 0; i < N; ++i) {
if(b[i] != b_expected[i]){
printf("Incorrect output on sample %d. Expected %d, Received %d \n", i, b_expected[i], b[i]);
retval = 2;
}
}
#if 0 // Optionally write out computed values
fp=fopen("out.dat","w");
for (i=0; i<N; i++){
fprintf(fp, "%d\n", b[i]);
}
fclose(fp);
#endif
if(retval != (2)){
printf(" *** *** *** *** \n");
printf(" Results are good \n");
printf(" *** *** *** *** \n");
} else {
printf(" *** *** *** *** \n");
printf(" BAD!! %d \n", retval);
printf(" *** *** *** *** \n");
}
return retval;
}添加数据文件:
与创造testbench.c一样并且!放在testbench目录下,才能正常读取数据。
最后!进行RTL/C协同仿真,即Solution—>Run C/RTL Co-simulation,或者主界面综合按钮旁边的小对号。(协同仿真时总也找不到数据文件,第一次果然是紧张,最后对testbench进行了C simulation,仿佛就过了)。
3.优化综合
从上面的综合结果里看到,延迟是相当的大的,而且数据输入间隔也很大,这说明RTL模块综合的并不是,很好。所以对模块进行优化:
PIPELINE(流水线):
流水线就是在组合逻辑电路之间,加入一些寄存器,从而降低延迟。(想象一下,两级组合逻辑电路,不加寄存器,得到稳定的逻辑输出需要等待的传播延迟是两级之和,而加入寄存器之后,得到的时延就是这两级组合电路的延迟分别加上寄存器建立时间的最大值,而建立时间要比门电路的延迟小的多),所以,可以提高性能。
回到dct源文件,里面有两个嵌套for循环,对这两个for嵌套进行流水线设计(Directive,如果没有在windows下面的show view),找到对应的for循环,右键(Insert Directive),添加PIPELINE。再进行综合:

延迟瞬间小了很多,但是毕竟资源换来的延迟,多用了一些寄存器了。
DATAFLOW(数据流):
观察上面那个图,Latency和Interval差不多,这样数据吞吐率不高,怎么优化呢?
在dct.c中,对dct函数(Insert—>Directive),添加DATAFLOW,然后综合(只允许顶层添加dataflow,下层添加没有用):
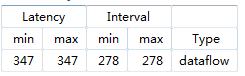
这样好像Interval降低了,Interval小于Latency,表明当前输入数据输出之前,可以再输入一个新数据。提高了吞吐率(dataflow)。
整体优化过程:
首先打开:Window analysis perspective,观察整个函数的延迟。

dct_2d延迟达到2644,而dct1延迟只有145,所以打开dct2。
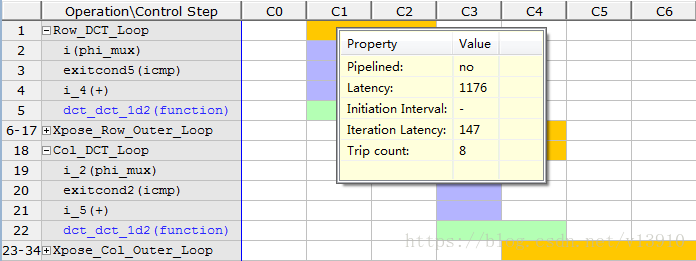
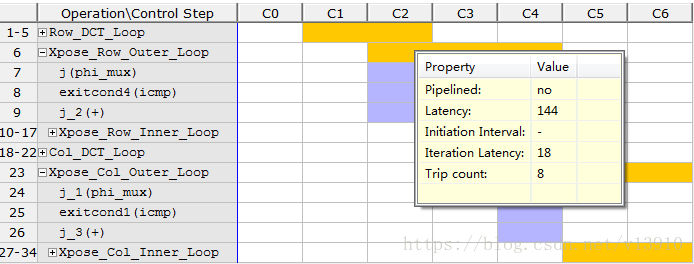
在dct2中,行列转换延迟达到1176,而转置操作只有144,所以在行列变换加入流水线。这时优化延迟量:

已经缩小了很多。。。继续优化一下,对顶层模块,添加DATAFLOW。

发现,Interval突然降低了,说明,吞吐量变大了。
最后把dct2放到Hierarchy顶层,这样就能用顶层dataflow进行优化了,对dct2添加INLINE。
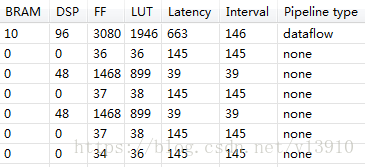
Interval已经降到146了,达到了性能要求。

行列变换一共用了96个DSP,资源换来了时序。