版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/Peng_yuyan_SDU/article/details/109693511
笔者最近拿到了一块Ultra96v2的开发板,尝试部署一个用于cifar10数据集识别的卷积神经网络,算是入门异构版型开发的demo实现吧。由于是第一次接触此部分内容,若有部分偏颇还请批评斧正。
1. 板子及工作流程简要介绍
Ultra96-V2板子中集成了一块ARM硬核(processing system,PS端)和一块FPGA软核(programmable logic,PL端),其中PS端通常用来处理一些便于CPU进行的调度运算,例如一些常见的预处理指令等;PL端通常用来处理一些大规模并行运算,以逻辑电路的形式实现算法,例如实现卷积神经网络等需要高速并行运算等需求。并使用xilinx提供的AXI总线完成PL和PS端的互联互通。
Ultra96-V2支持使用PYNQ进行开发,PYNQ提供了一种利用Python在顶层通过overlay方式烧录FPGA相关的IP核,其主要构架如下图所示:
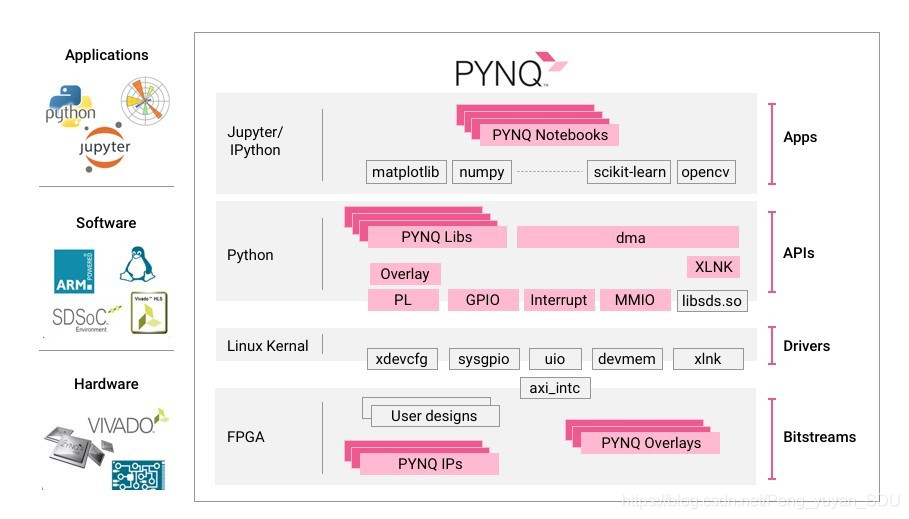
2.开发环境搭建
这里我们在PYNQ官网下载相关镜像,选择Borads,然后下载用于Ultra96v2的镜像:
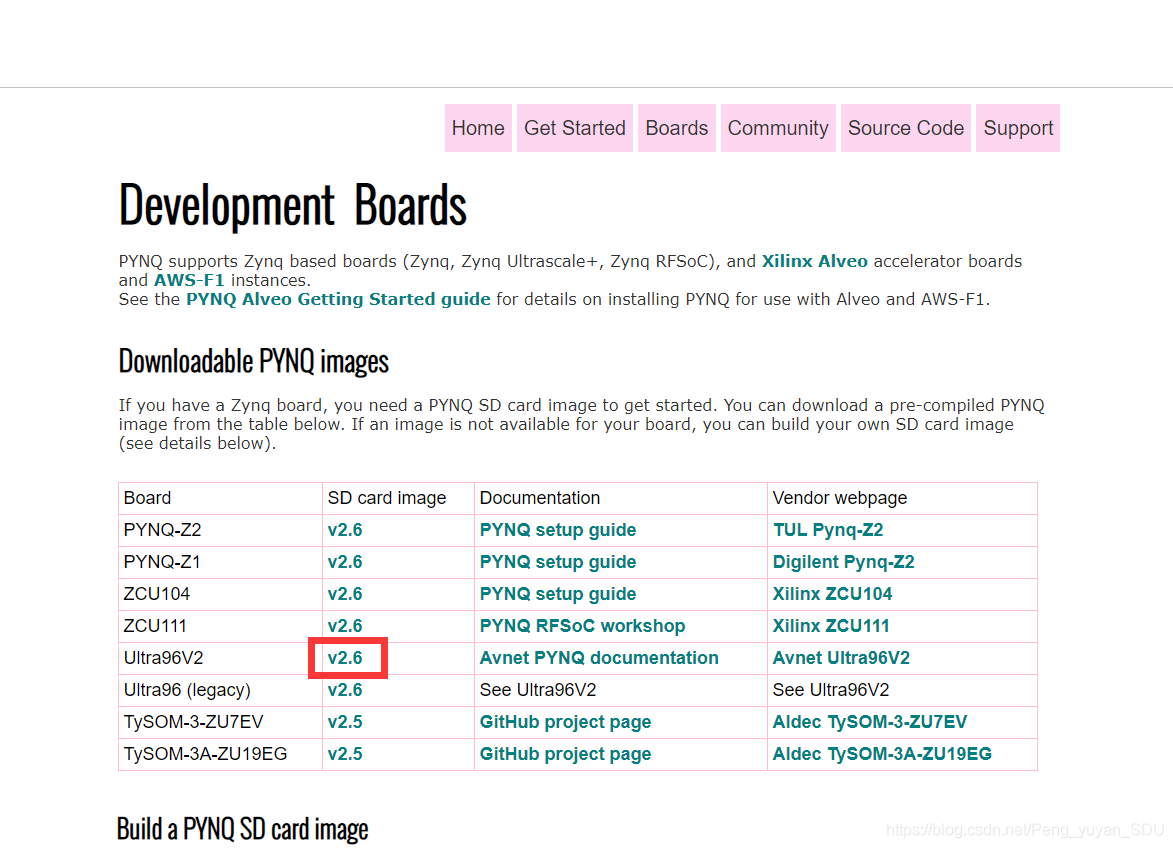
由于笔者在后续开发中发现v2.6版本会将“找不到hwh文件”这一问题识别为一个error,而v2.5版本则是waring可忽略,仅用tcl和bit流文件即可实现Overlay调用,所以笔者后续开发使用的为v2.5版本。PYNQ官网中并没有给出v2.5版本的旧版镜像,这里给出适用Ultra96v2等安富利公司一些开发板的旧版本镜像汇总,建议使用v2.5版本。下载完镜像后,使用Win32 Disk Imager将下载的ISO镜像烧录至SD卡中,烧录完成中将SD卡插入板子,并将拨码开关拨至SD卡启动模式(SW3_1 = OFF, SW3_2 = ON),至此PYNQ环境搭建完成。
3. 系统框图及卷积神经网络模型
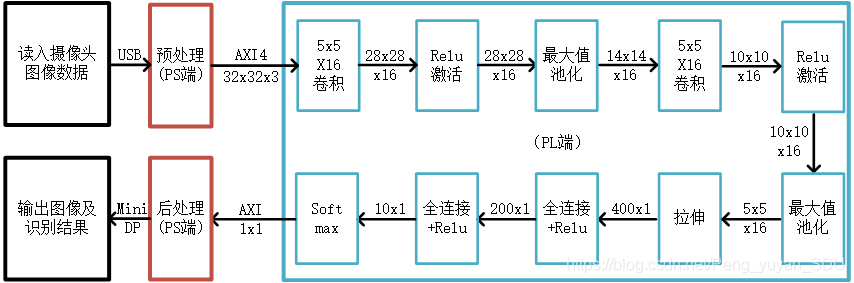
由于开发板BRAM资源有限,无法实现大规模模型,在这里我仅训练了一个非常基础非常小型的卷积神经网络模型作为入门。后续部署大型模型时可采用模型压缩方法降低BRAM利用率。在整个流程中,PS端通过USB读取图像信息,再进行预处理,例如切换为RGB通道、resize为32x32等;后送入PL端执行两层卷积、激活、池化,两层全连接网络后输出识别结果输出至PS端;PS端根据输出的数字0~9判断得到的识别结果,并将其和图像一起通过MiniDP接口输出至外接显示器。
4. 训练模型参数
在python3.7,tensorflow2.1环境中训练卷积神经网络模型,并将参数保存至txt文件中。这里建议导出参数时的输出方式和C语言的变量定义方式一致,方便下一步导入HLS的头文件中。相关训练代码已上传至Github,参见后记。对tensorflow代码基础不扎实的读者可学习北京大学曹健副教授开设的MOOC课程:《tensorflow笔记》。
5. Vivado HLS代码编写
在PL端的IP核编写过程中,读者可利用Xilinx公司提供的HLS高级语言综合工具,即利用C、C++、SystemC等语言编写相关描述代码,HLS等EDA软件可将C等高级语言综合为Verilog、VHDL等硬件描述语言,并生成IP核,还可进行C仿真、RTL/C联合仿真等。
5.1 顶层函数设计
void predict(uint8_t *in_b,uint8_t *in_g,uint8_t *in_r,uint8_t *out_t)
{
#pragma HLS INTERFACE m_axi depth=1024 port=in_b offset=slave bundle=part_b
#pragma HLS INTERFACE m_axi depth=1024 port=in_g offset=slave bundle=part_g
#pragma HLS INTERFACE m_axi depth=1024 port=in_r offset=slave bundle=part_r
#pragma HLS INTERFACE m_axi depth=1 port=out_t offset=slave bundle=part_out
#pragma HLS INTERFACE s_axilite register port=in_b bundle=control
#pragma HLS INTERFACE s_axilite register port=in_g bundle=control
#pragma HLS INTERFACE s_axilite register port=in_r bundle=control
#pragma HLS INTERFACE s_axilite register port=out_t bundle=control
#pragma HLS INTERFACE s_axilite register port=return bundle=control
DTYPE img[IMG_DMNIN][IMG_DMNIN][IMG_CHANNELS];
uint8_t in_b_buffer[IMG_DMNIN*IMG_DMNIN];
uint8_t in_g_buffer[IMG_DMNIN*IMG_DMNIN];
uint8_t in_r_buffer[IMG_DMNIN*IMG_DMNIN];
memcpy(in_b_buffer,in_b,IMG_DMNIN*IMG_DMNIN * sizeof(uint8_t));
memcpy(in_g_buffer,in_g,IMG_DMNIN*IMG_DMNIN * sizeof(uint8_t));
memcpy(in_r_buffer,in_r,IMG_DMNIN*IMG_DMNIN * sizeof(uint8_t));
for(uint8_t r = 0; r < IMG_DMNIN ;r++)
{
for(uint8_t c = 0; c < IMG_DMNIN ; c++)
{
img[r][c][0] = in_r_buffer[r*IMG_DMNIN+c];
img[r][c][1] = in_g_buffer[r*IMG_DMNIN+c];
img[r][c][2] = in_b_buffer[r*IMG_DMNIN+c];
}
}
//第一轮CAP处理,即卷积、激活、池化。
DTYPE layer_C1_out[C1_OUT_DMNIN][C1_OUT_DMNIN][C1_N_FILTERS];
DTYPE layer_P1_out[P1_DOWNSIZE][P1_DOWNSIZE][C1_N_FILTERS];
convolution_c1(img,weights_C1,layer_C1_out,biases_C1);
relu_a1(layer_C1_out,layer_C1_out);//为了节省内存,让输入和输出占用同一块内存
pooling_p1(layer_C1_out,layer_P1_out);
//第二轮CAP处理, 即卷积、激活、池化。
DTYPE layer_C2_out[C2_OUT_DMNIN][C2_OUT_DMNIN][C2_N_FILTERS];
DTYPE layer_P2_out[P2_DOWNSIZE][P2_DOWNSIZE][C2_N_FILTERS];
convolution_c2(layer_P1_out,weights_C2,layer_C2_out,biases_C2);
relu_a2(layer_C2_out,layer_C2_out);//为了节省内存,让输入和输出占用同一块内存
pooling_p2(layer_C2_out,layer_P2_out);
//拉伸
DTYPE layer_Flatten_out[FLAT_VEC_SZ];
flatten(layer_P2_out,layer_Flatten_out);
//两层全连接,每层全连接后跟一个激活。
DTYPE layer_D1_out[F1_ROWS];
DTYPE layer_D2_out[F2_ROWS];
vec_mat_mul_f1(layer_Flatten_out,weights_F1,biases_F1,layer_D1_out);
relu_a3(layer_D1_out,layer_D1_out);//为了节省内存,让输入和输出占用同一块内存
vec_mat_mul_f2(layer_D1_out,weights_F2,biases_F2,layer_D2_out);
relu_a4(layer_D2_out,layer_D2_out);//为了节省内存,让输入和输出占用同一块内存
softmax(layer_D2_out,out_t);
}
读者需要注意的是,在配置m_axi时,应注意depth深度的设置,笔者在之前一直设置为512,后续发现C仿真、RTL/C仿真的结果不一致,经过调试发现depth过小,导致读取的内存片段有误。这里由于输入分为RGB三通道,每一通道输入为32*32=1024,故depth设置为1024,输出仅为一位0~9的数字,故设置depth=1。 其他函数,例如卷积、激活、池化等代码不再详细展开,请参见后记,已上传至Github。
5.2 HLS优化
在编写神经网络的前向传播中,用到了大量的for循环,例如卷积网络是六层循环。在解决这些循环时,传统的CPU的中是通过调度进行串行计算。但在FPGA中,由于要尽可能地降低计算的时间延迟,则有这两种优化方式:
(1)pipeline。即流水线方式。比如你要组装一部手机,其中分为三个步骤,每个步骤需要使用不同的设备。有两种组装方式。假设每个步骤需要的时间为 1。组装完了一个设备之后再组装另一台。则传统的串行方式组装 5 台的时间为 15;当使用流水线方式时,当第一台手机完成第一个步骤后,第二台手机开始第一部分的组装。则总时间为 7。使资源得到重复利用。
(2)unroll。即循环展开方式。比如你要组装一部手机,其中分为三个步骤,每个步骤需要使用不同的设备。假设每个步骤需要的时间为 1。当使用unroll方式时,即并行运算,相当于五个工人同时组装,总时间为 5。
对于开发板来说,优化的目的一般就是两个:降低延迟、降低资源利用率(如BRAM,FFT等)。而这二者恰恰类似于了通信的可靠性和有效性,不可兼得。上面的两种优化方式明显提升网络的运算速度,降低延迟,但却会导致BRAM等资源利用率急剧提高。所以在优化过程中并没有绝对的好与坏,在特定的资源下实现尽可能低的延迟,是我们想要的最优结果。
相关配置方法可在Directive中选择:
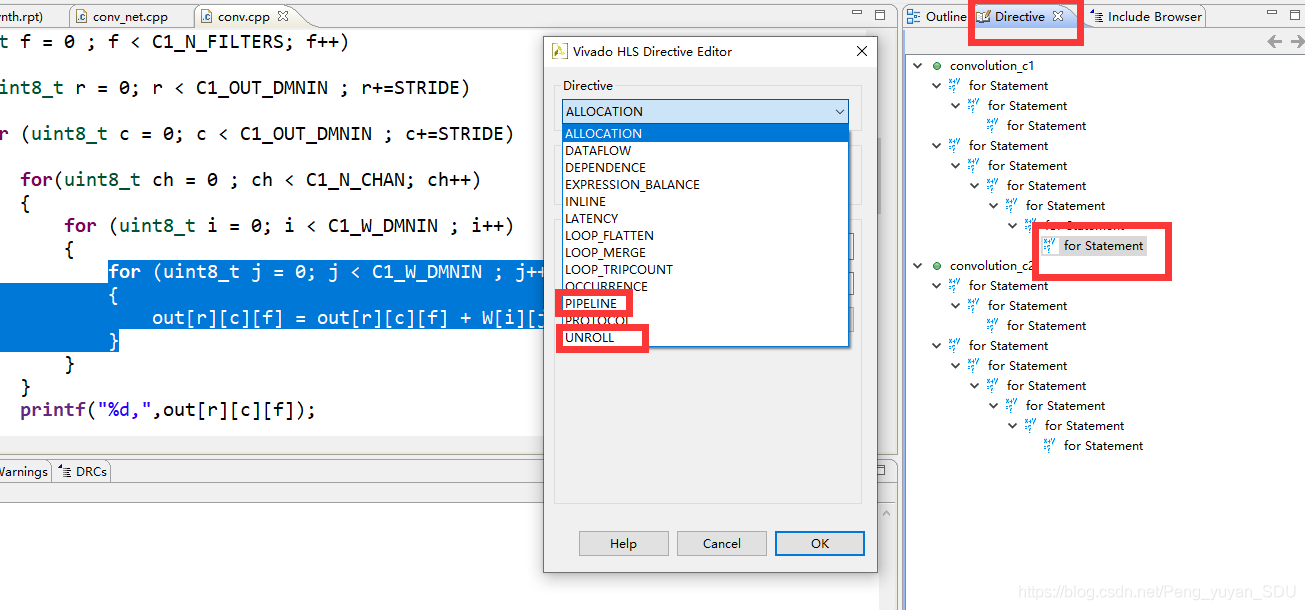
6. Vivado中Bolck Design设计
在Vivado HLS中完成代码后,通过C仿真、RTL/C仿真、综合后我们可以导出IP核,并在Vivado中完成下一步设计:
(1)将IP核导入到工程中。在HLS工程文件夹下找到\solution1\impl\ip,将ip整个文件夹复制到Vivado项目目录下。并在Vivado项目中,Settings→IP→Repository,将ip目录添加至项目中。
(2)Create Bolock Design,将Zynq UltraScale+ MPSoC和Predict(第一步添加的ip核)添加到BD中,并将Zynq核的PS-PL接口设置为1个master接口,4个Slave接口。连接Predict的interrupt到Zynq的pl_ps_irq端口,即完成ps和pl端的中断信号匹配。然后run Connection Automation,保证ps端和pl端的接口互联且不冲突即可。
(3)右键Bolock Design,Generate Output Prouducts,然后Create HDL Wrapper即可。

(4)运行Synthesis→运行Implementation→运行Generate Bitstream, 然后点击File→Export,将BlockDesign和Bitstream保存到工程根目录下,然后将其命名为同一名称。
7. PS端完成模型功能
将搭载PYNQ v2.5版本镜像的Ultra96v2上电开机(按下SW4),并使用micro USB连接到电脑。在电脑端使用Chrome或最新版Edge登录192.168.3.1,使用密码xilinx登录至jupyter界面,对板子进行操控。将步骤6中生成得到的tcl和bit文件上传到板子中,并建立.ipynb文件将这段代码拷入:
# import package
import math
from pynq import Overlay
from PIL import Image as PIL_Image
from pynq.lib.video import *
from PIL import ImageDraw as PIL_ImageDraw
from PIL import ImageFont
import matplotlib.pyplot as plt
import numpy as np
from pynq import MMIO
from pynq import Xlnk
import time
import ctypes
import cv2
# Load overlay and IP
overlay = Overlay("cifar10_pynq.bit")
xlnk = Xlnk()
xlnk.xlnk_reset()
img_in_b = xlnk.cma_array(shape=(1024,),dtype = np.uint8)
in_buffer_address_b = img_in_b.physical_address
img_in_g = xlnk.cma_array(shape=(1024,),dtype = np.uint8)
in_buffer_address_g = img_in_g.physical_address
img_in_r = xlnk.cma_array(shape=(1024,),dtype = np.uint8)
in_buffer_address_r = img_in_r.physical_address
img_out = xlnk.cma_array(shape=(1,),dtype = np.uint8)
out_buffer_address = img_out.physical_address
#load the image
def load_img(img):
img = frame_in
print("Open pictrue success!")
img = img.resize((32,32))
img_r,img_g,img_b = img.split()
image_array_r = np.array(img_r,dtype = 'uint8')
image_array_g = np.array(img_g,dtype = 'uint8')
image_array_b = np.array(img_b,dtype = 'uint8')
image_array_r = image_array_r.reshape(32*32,)
image_array_g = image_array_g.reshape(32*32,)
image_array_b = image_array_b.reshape(32*32,)
print("img_b array shape:",image_array_b.shape)
print("img_b array dtype:",image_array_b.dtype)
np.copyto(img_in_b,image_array_b)
np.copyto(img_in_g,image_array_g)
np.copyto(img_in_r,image_array_r)
IP_BASE_ADDRESS = 0x0080000000
ADDRESS_RANGE = 0x40
FPGA_img_addr_AP_CTRL = 0x00
FPGA_img_addr_GIE = 0x04
FPGA_img_addr_IER = 0x08
FPGA_img_addr_ISR = 0x0c
FPGA_img_addr_b = 0x10
FPGA_img_addr_g = 0x18
FPGA_img_addr_r = 0x20
FPGA_img_addr_out = 0x28
def CIFAR_Init_EX():
#mapping memory
mmio = MMIO(IP_BASE_ADDRESS,ADDRESS_RANGE)
while True:
ap_idle = (mmio.read(FPGA_img_addr_AP_CTRL)>>2)&0x01
if(ap_idle):
break
mmio.write(FPGA_img_addr_b , in_buffer_address_b)
mmio.write(FPGA_img_addr_g , in_buffer_address_g)
mmio.write(FPGA_img_addr_r , in_buffer_address_r)
mmio.write(FPGA_img_addr_out ,out_buffer_address)
mmio.write(FPGA_img_addr_GIE , 0)
mmio.write(FPGA_img_addr_AP_CTRL , 1)
while True:
ap_done = (mmio.read(FPGA_img_addr_AP_CTRL)>>1)&0x01
if(ap_done):
break
print("b_address:",mmio.read(FPGA_img_addr_b))
print("g_address:",mmio.read(FPGA_img_addr_g))
print("r_address:",mmio.read(FPGA_img_addr_r))
print("out_address:",mmio.read(FPGA_img_addr_out))
#Set Contrl Registers State Or Value
def cifar_main():
start = time.time()
CIFAR_Init_EX()
stop = time.time()
time_cifar_fpga = stop -start
print("cifar FPGA time:",time_cifar_fpga)
cifar_out = np.zeros(1,dtype = np.uint8)
cifar_out = img_out.copy()
return cifar_out[0]
def num_to_string(num):
numbers = {
0 : "get_airplane",
1 : "get_automobile",
2 : "get_bird",
3 : "get_cat",
4 : "get_deer",
5 : "get_dog",
6 : "get_frog",
7 : "get_horse",
8 : "get_ship",
9 : "get_truck",
}
return numbers.get(num,None)
img_w = 448
img_h = 448
videoIn = cv2.VideoCapture(0)
videoIn.set(cv2.CAP_PROP_FRAME_WIDTH,img_w)
videoIn.set(cv2.CAP_PROP_FRAME_HEIGHT,img_h)
print("capture device is open: " + str(videoIn.isOpened()))
flag,frame = videoIn.read()
timeF=10
c=1
while True:
flag,frame = videoIn.read()
c=c+1
if ((c%timeF==0)&flag):
frame_in = PIL_Image.fromarray(cv2.cvtColor(frame,cv2.COLOR_BGR2RGB))
load_img(frame_in)
plt.imshow(frame_in)
plt.show()
test = num_to_string(cifar_main())
print (test)
8. 实现功能演示
最终实现的效果: