在上周举办的 2020 世界超算大会(SC20)上,赛灵思通过现场演示,展示了赛灵思 Alveo 加速器卡与 AMD ROCm™ 开放软件平台的集成。该技术预演基于 AMD 高性能计算技术领域的领先地位,特别运用了用户模式队列和共享虚拟存储器,在 Alveo 加速器上提供直接、低时延的工作分派。
Alveo 加速器用于在高性能计算应用中提供计算、联网和存储加速。赛灵思器件在加速基础设施和专用计算方面发挥着关键作用,与 GPU 和 CPU 配合工作,能支持世界上大多数要求最严苛的工作负载,例如机器学习推断、实时视频转码和数据库分析。
SC20 技术演示展示了 Alveo 加速卡如何通过支持 PCIe 地址转译服务(ATS)及用户空间队列与事件,来进一步增强功能。这些服务允许 Alveo 使用通用虚拟地址空间访问系统和 GPU 内存。运行时用来控制可见性,并安全地隔离每个用户的存储器访问,以高效的用户模式操作方法实现工作分派和同步。
这些新的硬件特性,让赛灵思 FPGA 能够深入广泛地与 AMD ROCm 开放软件平台集成,为 AMD Instinct™ GPU 加速器与赛灵思 Alveo 加速器在计算、联网和存储解决方案中的无缝集成奠定基础。
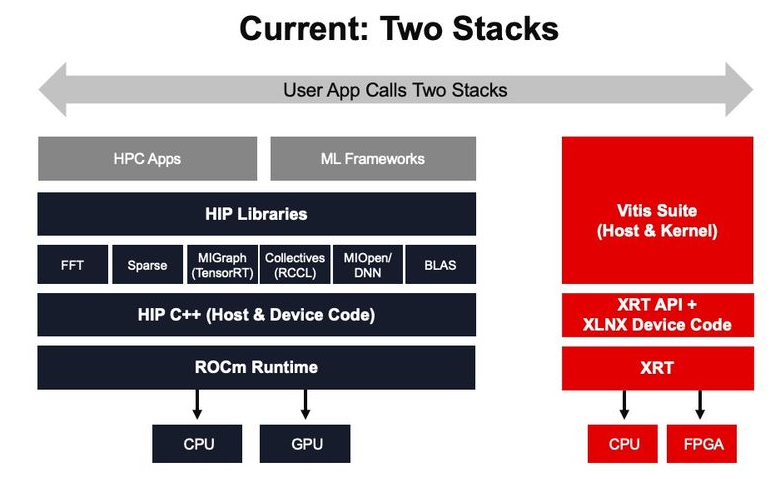
(独立的软件堆栈:AMD ROCm 和赛灵思 Vitis 软件)
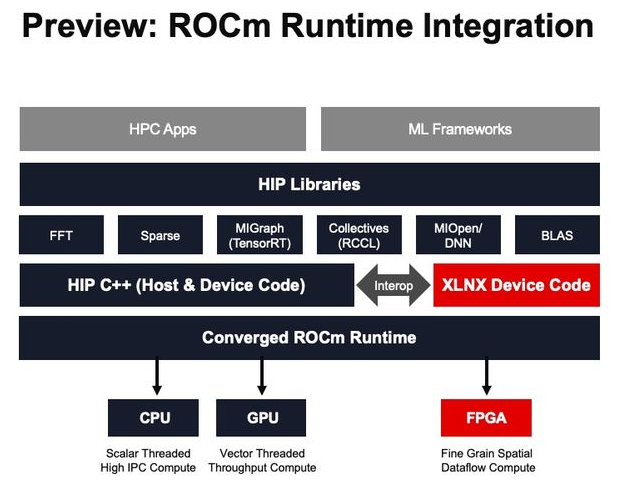
(技术演示:CPU、GPU、FPGA 的融合运行时)
本次技术演示展示的内容:
◀ 使用 AMD ROCm 开放软件平台上的融合运行时,统一探索和预留 AMD 和赛灵思加速器;
◀ 使用与 AMD Instinct 加速器低时延工作分派相同的用户 – 空间队列,将工作分配给 Alveo 加速器;
◀ 在 GPU 和 FPGA 器件之间实现点对点同步;
◀ 以及使用共同的共享虚拟地址空间,访问 GPU、CPU 和 FPGA 器件上的存储器 ;
AMD 的 SC20 在线展台也播出了该联合技术演示的视频。
AMD CPU、GPU 与赛灵思 FPGA 结合所创造的机遇令人满怀欣喜。今天的演示,是迈向百亿亿次计算(Exascale computing,E级计算/艾级计算)普及化的实质性第一步。该解决方案分别运用了上述两种平台在高吞吐量浮点计算和优化网络方面的优势。
注:AMD、AMD 箭头标识、AMD Instinct、ROCm 以及组合均为超威半导体公司 (Advanced Micro Devices, Inc.)的商标。
文章来源:Xilinx赛灵思官微