基于vivado2020.1和zcu102开发板(rev1.1)开发项目,工程涉及DDR4(MIG)和PL端多个读写接口交互的问题,通过AXI interconnect进行互联和仲裁(采用默认配置)。一个完整控制周期内(约100ms),各端口读写情况如下(AWSIZE均为4):
AXI1:只写入,AWLEN=119,每次写请求共计4320次突发写,完整控制周期内1次读请求
AXI2:读写,ARLEN=35,AWLEN=3,每次读请求共计56-232次突发读,写请求共计192-384次突发写,完整控制周期内读写请求各176次
AXI3:读写,ARLEN=5-6,AWLEN=3,每次读请求共计56-232次突发读,写请求共计192-384次突发写,完整控制周期内读写请求各60次
AXI4:读写,ARLEN=7,AWLEN=127,每次读请求共计320-1152次突发读,写请求共计62-128次突发写,完整控制周期内1次写请求,48次读请求
AXI5:只读,ARLEN=127,每次读请求共计3240次突发读,该模块是HDMI显示模块(1920*1080*3)的输入,频率为60Hz,它的读操作是独立于控制周期的
AXI3与AXI4的读会同时请求相同内存区域的数据,AXI4的写与AXI5的读会访问相同内存区域的数据。
AXI2-AXI4是计算模块的输入输出接口,设计之初默认DDR读写速度远高于计算速度,DDR读写会先于计算完成。因此在设计计算模块控制逻辑的时候,没有考虑ddr读写相关的握手信号。但在实际验证过程中,各通道会随机出现阻塞,因此会导致DDR读写地址乃至控制逻辑的错乱。
经过估算DDR带宽是远高于读写数据带宽的,为了解决这一问题,包括但不限于改变突发长度、调整AXI interconnect仲裁优先级等操作中的哪些会起到作用?
以及,一般涉及DDR读写仲裁的控制逻辑需要注意哪些方面?
注:控制逻辑产生的问题是,以AXI2为例,它的176次读写是分为176个子阶段完成的,阶段1首先读取第1批读数据后,开始对第1批数据进行计算,同时开始读取第2批数据。之前默认读一定快于计算,所以以计算完成作为状态转移的标志,在计算完成后发出第1批数据的写请求后,进入第2阶段的逻辑。在该阶段计算第2批数据的同时,读入第3批数据,并完成第1批数据的写入。同样默认读写一定快于计算,在计算完成后,发出第2批数据的写请求,并进入第3阶段。阻塞会导致读数据晚于计算完成,在此情况下,所有的控制逻辑都会发生错乱,DDR的读写地址将不受预期的控制。
问题解答:
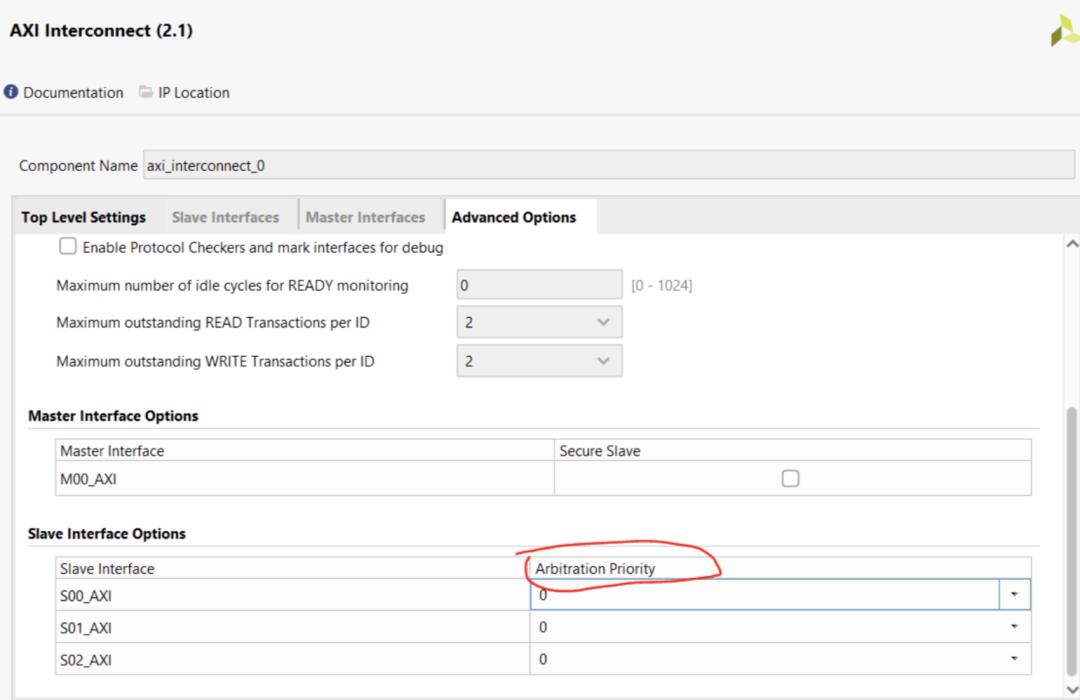
通常如果你多个端口同时访问DDR,就会发生阻塞,你可以通过设置priority的方式(如下图),设置优先的通道。
并且建议你的optimization strategic设置成 Maximum Performance,提高interconnect本身的时钟频率。
关于 DDR(MIG),如果你都是地址随机读写的话,并且长度一致的话,DDR效率可以变得很低,这是你的系统设计需要注意的。
有关DDR的效率问题,可以到IP应用的板块进一步咨询。