新智元报道
来源:bdtech
编辑:白峰
【新智元导读】深度学习的突飞猛进,给GPU插上了腾飞的翅膀,英伟达和AMD的显卡成为人工智能的「硬通货」。但是GPU固有的一些缺陷,让它的大规模应用受到约束,更加抗造的FPGA有望成为AI新的「底层建筑」。
过去十年,人工智能搅局了很多传统行业,也给显卡带来了福音。
说显卡,好像等同在说英伟达,其实不光英伟达,AMD的显卡在过去十年也是突飞猛进。

GPU目前来看是最通用的深度学习处理器,英伟达也乘着东风,摇身一变成为云GPU服务提供商,它的人工智能实验室也出了很多SOTA结果。
但是,专门研究机器学习软件的研究显示,GPU 也存在固有的缺陷,将其大规模应用于人工智能应用还有很多挑战。
而现场可编程门阵列(FPGA) 有望弥补这些缺陷。FPGA 在制造后仍可以高度定制的处理器,它比一般处理器更有效率。然而,FPGA很难编程,这个问题需要解决。
专业化的人工智能硬件,已经成为深度学习处理引擎的一个趋势,国内也有很多公司在开发各种AI加速卡,深度学习的最佳基础设施到底会花落谁家?
文章来源:腾讯网
GPU 矩阵运算很强,但「抗压」不行还费电
三维图形卡是 GPU 拥有如此多内存和计算能力的原因,它与深层神经网络有一个共同点:需要大量的矩阵乘法运算。
图形卡可以并行执行多个矩阵运算,这极大地加快了运算速度。图形处理器可以将训练神经网络的时间从几天、几周缩短到几小时、几分钟。
GPU 在深度学习领域的吸引力已经催生了一系列公共云服务,这些服务为深度学习项目提供强大 的GPU 虚拟机。
但是图形卡也有硬件和环境的限制,神经网络训练通常不会考虑运行神经网络的系统在部署过程中遇到的困难,GPU 实际使用时就会有额外的压力。
另外,GPU 的能耗很高,需要大量的电力,还得用风扇来冷却。

如果在台式机、笔记本电脑或者服务器机架上训练神经网络时,这并不是什么大问题。
但是部署深度学习模型的环境对 GPU 并不友好,比如自动驾驶汽车、工厂、机器人和许多智能城市的配置,在这些环境中,硬件必须能够承受如发热、灰尘、湿度、运动和能耗限制。
一些重要的应用如视频监控,要求硬件暴露在对 GPU 有负面影响的环境(例如太阳)中,而GPU 使用的晶体管技术已经逐渐见顶,发热问题在很多情况下已经成为掣肘因素。
寿命也是一个问题。一般来说,GPU 的使用时间大约为2-5年,对于每隔几年就更换电脑的游戏玩家来说,这并不是一个大事。
但是在其他领域,比如智能汽车行业,人们期待着更高的耐用性,GPU要想用在车上,就要抗震抗噪防潮等,GPU的设计会更麻烦。
以自动驾驶为例,「自动驾驶汽车的软件要想商用,至少需要7-10个 GPU (其中大部分将在不到4年内失效) ,对于大多数购车者来说,智能或无人机的成本变得不切实际。
其他行业如机器人技术、医疗保健和安全系统也面临类似的挑战。
FPGA加持的深度学习, 推理速度和吞吐量远超GPU
FPGA 是可定制的硬件设备,具有各种适应性组件,可以针对特定类型的计算体系结构进行优化,如卷积神经网络。
它们的可定制性降低了电力需求,并在加速和吞吐量方面提供了更高的性能。它们的寿命也更长,大约是 GPU 的2-5倍,并且对恶劣的环境更有抵抗力。
一些公司已经在他们的人工智能产品中使用了 FPGA。微软就是一个例子,它提供了基于 FPGA 的机器学习技术作为 Azure 云服务的一部分。
但是 FPGA 的问题是它们很难编程。配置 FPGA 需要硬件描述符语言(如 Verilog 或 VHDL)的知识和专业技能。

现在的机器学习程序大多是用 Python 或 C 等高级语言编写的,将它们的逻辑转换为 FPGA 指令非常困难,使用 TensorFlow、 PyTorch、 Caffe 和其他框架在 FPGA 上运行神经网络通常需要大量的人工时间和精力。
要对 FPGA 进行编程,需要组建一个同时了解 FPGA 的硬件和神经网络的优秀团队,花几年时间开发一个硬件模型,并在面临高使用率或高频率问题的同时为 FPGA 编译它。
与此同时,还需要具备广泛的数学技能,以较低的精度准确计算模型,还需要一个软件开发团队将人工智能框架模型映射到硬件架构。
Mipsology 试图弥合这个鸿沟,推出了一个名为Zebra的 软件平台,允许开发人员轻松地将深度学习代码移植到 FPGA 硬件上。
它提供了一种软件抽象层,可以隐藏通常需要高水平 FPGA 专业知识才能实现的复杂性,只需输入一个 Linux 命令,Zebra 就可以工作了——它不需要编译,不需要更改原来的神经网络,也不需要学习新的工具,而且可以使用 GPU 来训练。
ASIC不够灵活,FPGA 更有可能成为深度学习的「底层建筑」
一个可以将深度学习代码转换为 FPGA 硬件指令的抽象层,应该使用怎样的架构?
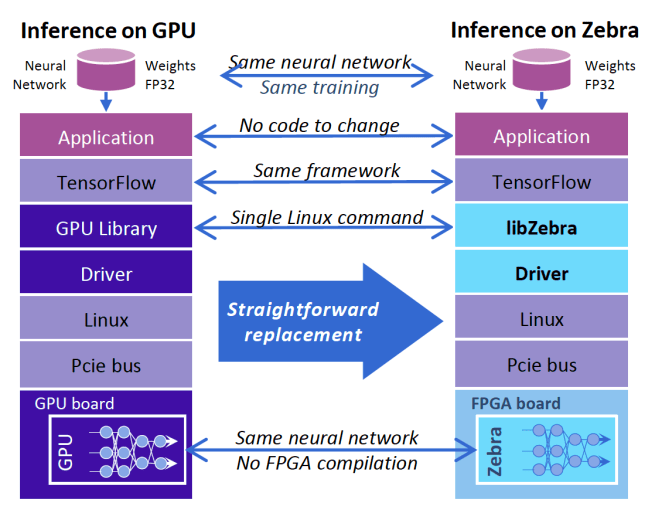
上图描述的只是众多探索在人工智能项目中使用 FPGA 方法的一种,目前,Xilinx 已经将这个抽象层集成到其主板中。
其他公司,如谷歌和特斯拉,也在开发自己的专用人工智能硬件,并提供云端或边缘端的使用环境,还有在神经形态芯片方面的努力,这些专用芯片的体系结构是专为神经网络设计的。
除此之外,定制化集成电路(ASIC) 也在探索AI方面的应用,但ASIC通常是为一个非常具体的人工智能任务设计的,缺乏 FPGA 的灵活性,无法重新编程。

如果FPGA的开发成本大幅下降,而神经网络的性能又可提升很多,就可以在不替换硬件的情况下启动高效的 AI 推理。
FPGA 固件开发具有高效率、短周期的特点,未来在快速变化及环境要求严苛的领域,大有可为。
参考:https://bdtechtalks.com/2020/11/09/fpga-vs-gpu-deep-learning/
本文转载自:腾讯网