本文转载自:FPGA技术实战的CSDN博客
引言:我们在利用FFT IP核进行FPGA设计时,需要理解FFT相关的操作理论,比如FFT蝶形运算带来的位宽扩展、FFT实现资源与性能的权衡、如何实时更新FFT变换点数、缩放等相关配置及FFT操作时序等。本文我们就针对这些问题进行详细的介绍。
1.有限字长考虑
突发I/O架构通过连续地传递输入数据来处理一组数据阵列。在每个过程中,算法执行Radix-4或Radix-2蝴蝶运算(butterfly),其中每个butterfly分别获取四个或两个复数,并返回四个或两个复数在同一内存中。IP核返回内存的数字可能是大于从内存中提取的数字。必须采取策略适应这种动态范围扩展。
对于Radix-4 DIT FFT,在蝶形阶段计算出的值按照以下以下因子增长,即带来3bit位宽扩展。

公式1 Radix-4 DIT 蝶形计算位宽增长
对于Radix-2 DIT FFT,在蝶形阶段计算出的值可以通过以下因子增长,即会带来2bit位宽展宽。

公式2 Radix-2 DIT FFT蝶形计算位宽增长
Bit位宽的增长可以有三种处理方式:
1.1 全精度算法考虑
当使用全精度无缩放算法时,保留所有整数bit。数据路径位宽增加以适应蝶形运算带来的位宽增长。乘法产生的小数位数的增长在乘法后被截断(或舍入)。输出位宽为(input width+log2(transform length)+1),这是最坏的位宽增长场景。
考虑未缩放Radix-2 DIT FFT:每级数据路径必须增长1bit,因为蝶形中的加、减器可能会加/减两个满标度值并生成宽度增长1位的样本。这将产生输出宽度相对于输入宽度增加的log2(变换长度)部分。复数乘法器保持了输入数据幅度(当它在复数平面上应用旋转时),当输入幅度大于1时,理论上会产生bit位宽增长(例如,1+j会产生1.414倍的幅度增长)。这意味着复数乘法器bit增长必须在整个FFT处理中考虑。例如,16bit输入,包含1位整数位,15位小数位,1024点变换,将会有27bit位宽输出,其中12位整数,15位小数。注意,IP核没有明确二进制点的位置。输出保持和输入相同的二进制点位置。对于16位输入,3位整数,13位小数,输出将会是27bit,包括14位整数bit和13位小数位。
注意:对于未缩放算法、缩放算法和块浮点算法,IP核没有明确二进制点位置。输出数据二进制点位置和输入数据和每级缩放移位有关。
1.2.缩放算法考虑
当使用缩放处理,每级的缩放因子可以为1,2,4或者8。如果缩放不充分,碟形运算输出可能会带来位宽增长,超出动态范围,从导致溢出。当将缩放处理应用于FFT实现时,缩放因子s如下定义:

公式3 缩放因子定义
其中,bi为第i级的缩放因子。因此,使用缩放因子的FFT/IFFT输出结果,由因子1/s进行修正。
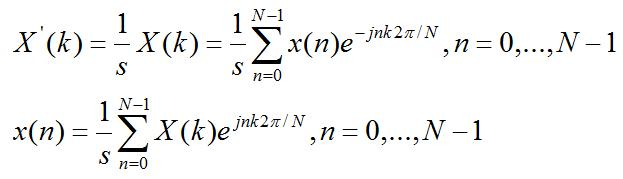
公式4 缩放因子对FFT/IFFT计算影响
如果Radix-4算法在每级使用因子4进行缩放,则因子1/s等效于IFFT中的1/N。对于Radix-2,每级缩放为2,由因子1/N提供。
1.3.块浮点算法考虑(自动缩放)
使用块浮点算法,每级采用充分的缩放,保证不溢出,缩放由块指数跟踪。
2.浮点考虑
FFT可选的接收32bit单精度浮点数据,包括1位符号位,8位整数位和23为小数位,该数据组织符合Xilinx浮点操作IP要求。在FPGA内部实现完全浮点需要消耗大量资源。FFT核浮点实现是利用高精度定点实现与完全浮点类似的噪声性能。
图3-14举例了两级噪声性能,通过选择24bit和25bit相位因子宽度。相位因子越宽消耗的资源越多。
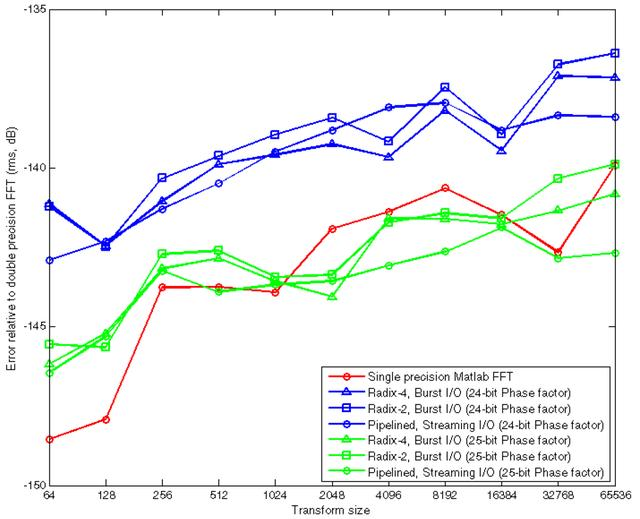
图1、FFT两级噪声性能对比
当将结果与第三方模型(例如MATLAB)进行比较时,应注意,通常需要一个比例因子来确保结果匹配。比例因子依赖于数据,因为输入数据规定了内部定点核心之前所需的标准化级别。由于核心在浮点模式下不提供此缩放因子,因此如果需要,可以在核心输出之后应用缩放。
当选择浮点输入数据时,所有优化选项(内存类型和DSP的优化)仍然可用,允许您在转换时间内权衡资源。
FFT核心的浮点接口不支持非规范化数字。为了匹配Xilinx浮点运算符核心的行为,核心将非规范化的操作数视为零,符号取自非规范化数字。
如果核心在输入端检测到NaN或±无穷大值,则与当前输入帧相关联的所有输出样本都设置为NaN。符号位设置为零,所有指数和分数位都设置为1。
3.实数输入考虑
FFT核心接收复数数据样本,但可以通过将所有虚输入样本设置为零来对实值数据执行转换。
由于前面描述的有限字长效应,在转换过程中引入噪声,导致输出数据不是完全对称的。DIT和DIF FFT算法由于计算顺序的不同而产生不同的噪声影响。噪声在低频仓中更为突出。因此,Xilinx建议在执行实数FFT时使用输出数据的上半部分(N/2+1到N个点)。
4.舍入实现
在所有体系结构中,都有一个选项,可以对蝶形阶段之后的数据应用收敛舍入。但是,选择此选项不会对数据路径中发生字长缩减的所有点应用收敛舍入。
特别是,FFT数据路径中所有复乘法器的输出被截断,以减少数据路径宽度(同时仍然保持足够的精度),并在小数位数上添加一个简单的舍入常数。这个常数实现了非对称的、向负无穷舍入的四舍五入,并且可以在大量样本上给FFT结果引入一个小偏差。
5.FFT架构选择
FFT核提供了四种可选择的计算结构架构,可以在资源和转换时间之间进行权衡。具体包括:
流水线I/O:允许连续数据处理。
Radix-4突发I/O:使用迭代方法分别加载和处理数据。使用资源大小比流水线解决方案小,但转换时间较长。
Radix-2突发I/O:使用与基-4相同的迭代方法,但蝶形较小。使用资源比基-4更少,但转换时间更长。
Radix-2 Lite突发I/O:基于基2体系结构,该变体使用时间复用方法使用更小的内核执行蝶形运算,代价是转换时间更长。
图2说明了四种架构的吞吐量与资源使用之间的权衡。根据经验,每个体系结构提供的资源与下一个体系结构相差2倍。

图2、不同体系结构的资源与吞吐量比较
所有四种体系结构都可以配置为使用三种定点算术方法(未缩放、缩放或块浮点)之一的定点接口,也可以使用浮点接口。
5.1 自然序和倒序问题
每个体系结构都提供了输入数据按自然顺序,输出数据按自然序或倒序的选择。FFT算法在处理过程中对样本进行重新排序,使得按自然顺序输入的数据以倒序顺序输出。IP核可以选择按自然顺序输出数据。然而,这会给每个架构带来成本(消耗更多资源,特别RAM资源)。对于突发I/O架构,这会带来转换时间变长,因为卸载数据不能与加载下一帧的输入数据同时进行,因此需要单独的卸载和加载阶段。在流水线结构中,它需要额外的RAM存储来执行重新排序,消耗更多RAM资源。
5.2流水线I/O架构
流水线I/O解决方案将几个基-2蝶形处理引擎模块化,以提供连续的数据处理。每个处理引擎都有自己的内存RAM来存储输入和中间数据(图3)。IP核能够为下一帧数据加载输入数据,同时对当前数据帧执行转换计算,并卸载前一帧数据的结果。您可以连续地传输数据,并且在计算延迟之后,可以连续地卸载结果,该结构允许每帧之间有间隙。

图3、流水线I/O架构
注意:连续流数据并不意味着可以忽略来自FFT核心的AXI4流等待状态。在某些情况下,FFT核心可能必须插入waitstates来暂停传入的样本数据。
在缩放定点模式下,数据在每对基数2阶后被缩放。块浮点模式可能比缩放模式使用更多的资源,因为它必须保持额外的精度以允许动态缩放而不影响性能。因此,如果输入数据被很好地理解并且不太可能出现大幅度波动,那么使用缩放算法(具有适当的缩放时间表以避免在已知的最坏情况下溢出)就足够了,并且可以节省资源。
5.3 Radix-4 Burst I/O(基-4突发I/O)
对于基-4突发I/O方案,FFT核使用Radix-4碟型处理引擎,如图4所示。它加载和卸载(输出)数据是独立的,数据I/O和处理不是同时进行的。当FFT开始,输入数据加载,在一帧完全加载完成后,FFT核计算转换。当计算完成后,数据可以输出,但是不能在计算过程中加载或者输出数据计算结果。如果数据以数字倒序卸载,则数据加载和数据卸载过程可以同时进行。从图4中,我们可以看到,蝶形运算输出结果反馈至数据输入侧RAM,实现RAM共享,减少资源使用。

图4、Radix-4 Burst I/O
该架构比流水线I/O架构使用更少的资源,但是转换时间变长,支持64~65536点转换。数据和相位因子可以存储在BRAM或者分布式RAM。
5.4 Radix-2 Burst I/O
对于基-2突发I/O方案,FFT核使用Radix-2碟型处理引擎,如图5所示。在一帧数据加载后,输入数据流必须挂起直到转换计算完成,然后数据才可以加载。和Radix-4突发I/O架
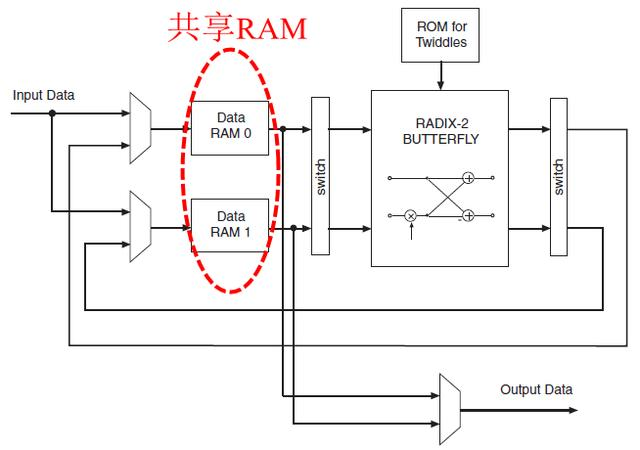
图5、Radix-2 Burst I/O
Radix-2 Burst I/O的架构与Radix-4 Burst I/O整体类似,只是蝶形运算结构不同。
5.5 Radix-2 Lite Burst I/O
该结构不同于Radix-2突发I/O碟形处理引擎,它使用共享的加法器/减法器,因此减少了资源以及碟形运算附加的延迟。和Radix-4突发I/O架构类似,如果数据以数字倒序卸载,则数据加载和数据卸载过程可以同时进行,该架构支持8~65536点转换。
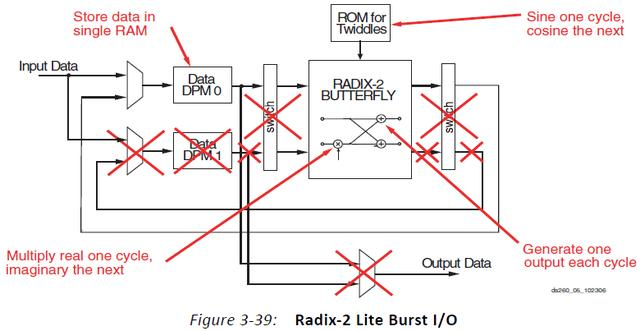
图6、Radix-2 Lite Burst I/O
Radix-2 Lite Burst I/O架构省略了更多的RAM资源及复用器资源,但换来更长的转换时间。
6.运行时配置FFT IP核
本节讨论的所有运行时配置选项都是使用配置通道编程的。有关更多信息,请参阅上篇文章配置通道。运行时配置主要包括FFT转换点数、FFT/IFFT配置、缩放因子及循环前缀插入等配置。运行时配置需要在FFT IP核界面中勾选Run Time Configurable Transform Length,如图所示。
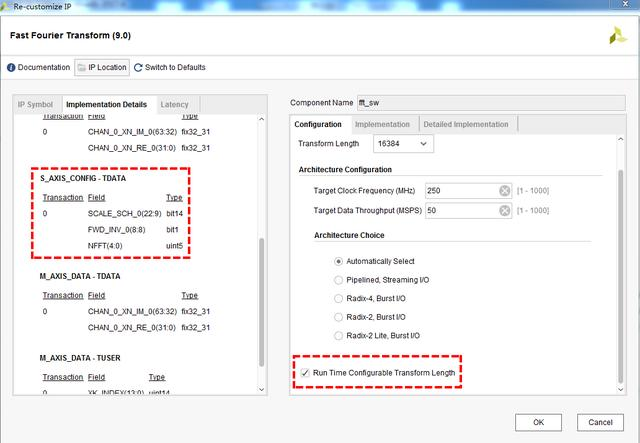
图7、运行时配置参数
6.1转换点数(NFFT)
FFT/IFFT IP核支持如图8所示转换点数,注意,每种架构支持的最新转换点数稍有不同。该参数在配置通道s_axis_config_tdata对应的NFFT字段进行配置。
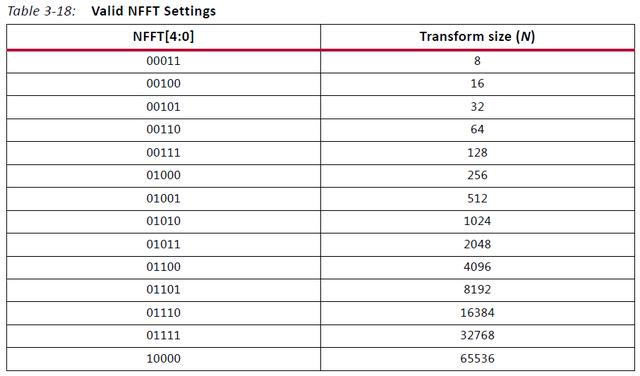
图8、FFT/IFFT核支持的转换点数
6.2 FFT/IFFT选择及缩放因子
FFT/IFFT的选择和缩放因子的配置也是通过s_axis_config_tdata端口进行的,在图7中可以看到这三个字段对应的占位顺序,注意每个字段都以8bit字节为符号边界。下面我们说下缩放因子的相关内容
Burst I/O架构缩放因子
在连续级缩放执行可以通过配置通道设置恰当的SCALE_SCH字段。对于Radix-4,突发I/O和Radix-2架构,SCALE_SCH字段值使用bit对[...N4,N3,N2,N1,N0],每对值对应于相应的缩放级。每级计算从stage0开始,使用2bit LSBs。级数计算通过log4(转换点数)或者log2(转换点数)计算Radix-4和Radix-2级数。在每级中,数据可以移位0,1,2,3bits,分别对应于SCALE_SCH值00,01,10,11。
例如,对于Radix-4,N=1024,缩放因子[01 10 00 11 10]。N=1024对应于5级碟形运算,因此stage0向右移动2bit,stage1移动3bit,stage2移动0bit,stage3移动2bit,stage4移动1bit。该缩放方案总计移位8bit,缩放因子为1/256。N=1024,在Radix-4突发I/O架构中,保守的方案SCALE_SCH=[10 10 10 10 11],避免溢出。在Radix-2架构中,保守的方案SCAHLE_SCH=[01 01 01 01 01 01 01 01 01 10],共10级缩放。
流水线I/O架构缩放因子
对于流水线I/O架构,考虑每对相邻的Radix-2级作为一组。例如,group0包含stage0和stage1,group1包含stage,2和stage3等等。每级缩放因子SCALE_SCH字段与突发I/O架构类似,[...,N4,N3,N2,N1,N0]。每个group缩放值对应于对应的2bit LSB值。例如,N=1024点,[10,10,00,01,11],则group0(包括stage0和stage1)右移3bits,group0(包括stage2和stage3)右移1bits,group2(包括stage4和stage5)右移0bits,group3(包括stage6和stage7)右移2bits,group4(包括stage8和stage9)右移2bits。对于该点数转换,保守的缩放因子SCALE_SCH=[10 10 10 10 11],避免数据溢出。如果转换点数不是4的幂次,则最后一组只有一级,该组最大bit增长为1bit,因此,最高两位MSBs只能为00或者01。对于N=512时,保守的缩放因子SCALE_SCH=[01 10 10 10 11]。
6.3循环前缀插入(CP)
循环前缀占用了FFT输出的一部分,它添加至转换开始的部分。输出数据包含了输出前缀(输出数据结束的复制),跟随在完整的输出数据,所有已自然序输出。循环前缀只在自然序输出可用。
当循环前缀使用,循环前缀的长度可以在不中断帧处理过程,在帧与帧之间插入。插入数据的长度可以设置为少于变换长度的任意值。该长度由配置通道CP_LEN字段设置。例如当N=1024时,循环前缀长度可以设置为0~1023任意值,CP_LEN=0010010110设置输出数据包含150个采样输出循环前缀值。
6.4 配置FFT IP核
FFT转换使用配置通道进行配置。当IP核加载新帧数据处理时,它会检查新配置是否应用配置通道,如果有,在帧加载前,FFT处理核使用新的配置。否则,IP核使用上一次配置信息。如果不对IP核进行配置,IP核使用复位默认配置。将配置数据应用于特定帧的过程取决于IP核的当前状态:
将配置应用于上电后或空闲期后的第一帧;
将配置应用于帧序列中的下一帧。
为了确保在帧处理前对IP核进行正确配置,配置信息应该使用以下时序写入配置通道:
实时模式:在写入第一个数据到数据输入通道前,配置数据写入配置通道完成至少一个时钟周期。如果写入失败,则IP核使用前一个配置进行变换。
非实时模式:配置数据写入可以发生在第一个数据写入数据输入通道前或者同时处理。
在系统设计中,最简单的方法是在系统初始化是就完成IP核相关初始化配置。
7.FFT转换状态问题
7.1 溢出问题
定点数据
数据输出和状态通道的OVFLO字段只在缩放算法中使用,当输出数据帧中任何点发生溢出时,OVFLO输出为高。对于多通道核,每个通道有独立的OVFLO字段。当核发生溢出时,转换数据不能用于大部分应用。
浮点数据
当FFT处理浮点数据时,溢出字段用于指示溢出指数幂。基于内部结果符号,输出采样溢出设置为±∞。当NaN值出现在输出时,溢出字段不会插入。当输入数据帧出现NaN或者±∞值时,FFT输出才会出现NaN值。
7.2 块指数
输出数据和状态通道BLK_EXP字段包含块指数幂(只用在块浮点选项中)。对于多通道核,每个通道包含包含独立的BLK_EXP字段。在该字段的值代表了转换过程中总的缩放比特。例如,如果BLK_EXP=00101=5,这意味着输出数据(XK_RE,XK_IM)缩放5bit(右移5bits),换句话说,为了完全使用输出数据路径可用的动态范围,防止溢出,输出结果除以32。
7.3 XK 索引
XK_INDEX字段(如果数据输出通道使用),给出了XK_RE/XK_IM数据采样编号。在自然序输出中,XK_INDEX从0增加至N-1(转换点数),当倒序输出时,XK_INDEX编号也为倒序输出。举例8点FFT,如表1所示。
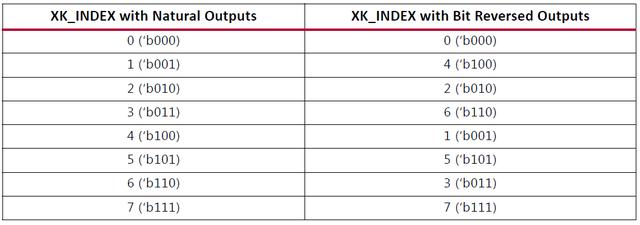
表1、8点FFT XK索引
当循环前缀使用时,首先卸载循环前缀,XK_INDEX计数从(N - (循环前缀长度))到(N-1)。循环前缀仅在自然序输出中使用。
8.FFT IP核操作时序
核心开始处理帧当出现:a)上游主机通过向进程提供数据来请求处理帧,以及b)当它能够处理时。选择的架构和循环前缀插入是影响内核何时能够处理新帧的主要配置选项。
下面的时序图是实际行为的概括,用于显示IP核在处理帧时经过的每个阶段,以及这些阶段如何可以(或不能)重叠。不同相位的长度不可缩放,并且处理时间可能比输入或输出帧所需的时间长得多。
特别是,由于数据输入通道对数据进行缓冲(非实时模式下16个符号,实时模式下1个符号),因此TREADY在输入数据通道上的行为并不完全准确。但是,这些数据在缓冲区中等待,直到FFT处理核心准备就绪。这些图中的数据输入信道TREADY用于指示FFT处理核心何时需要数据,而不是AXI信道(及其缓冲器)何时需要数据。
8.1 未使用循环前缀的流水线I/O时序
当使用流水线I/O架构,不插入循环前缀时,IP核可以将加载帧处理和之前帧输出同时处理。如果如果上游主模块在上一帧后立即输出新的数据帧,IP核会立即加载进行处理。图9显示了流水线架构中背靠背数据帧的一般处理时序。


图9、未使用循环前缀流水线架构处理时序
在图9中,可以看到首帧加载和处理的后的数据输出之间存在一定的延迟。该延迟取决于在Vivado IDE中IP核的参数设置。当该延迟过后,后续处理帧按照背靠背时序输出。
8.2 使用循环前缀的流水线I/O时序
当使用循环前缀插入时,处理后的帧长会大于加载的数据帧长。此时,IP核输入帧不能出现图3-42所示的背靠背帧,每个帧之间必须插入循环前缀长度的间隔,如图3-43所示。数据输入通道TREADY信号用于指示何时输入新帧。
它在卸载阶段进行扩展。

图11、使用循环前缀流水线架构处理时序
8.3 突发I/O架构
突发I/O架构不像流水线I/O那样允许帧重叠处理。当自然序输出使用,IP核开始加载下一帧前,需要完成当前帧处理和输出。
当倒序输出使用时,IP核仅在新帧加载时才输出数据。这意味着加载N+1帧会和输出N帧重叠。然而,当开始卸载数据帧时,如果上游主模块不提供数据到IP核,则IP核需要手动刷新输出,此时加载和卸载阶段不会发生重叠。
图12显示了自然序输出突发I/O架构一般转换时序。这需要完全分开的加载、处理和卸载阶段。上游模块不断尝试传输数据帧到下游从模块。该例子中没有显示循环前缀的影响,它在卸载阶段进行扩展。

图12、自然序突发I/O模数时序
如图12所示。上游主模块加载所有数据FrameA到FFT IP核数据输入通道,当FFT IP核处理该数据时,通道缓冲是不存在数据的。然而主模块立即开始发送Frame B,在图中A点处,由于FFT正在处理Frame A,不再从数据输入通道取数据,Frame B可以送入数据输入通道缓冲。当s_axis_data_tready变为低电平时,可以认为正在缓冲Frame B。数据输入通道一直处于等待状态,FFT无法接收上游主模块数据,直到B点。此时,FFT已经完成Frame A的输出,开始加载Frame B到处理核,这会读取数据输入通道缓冲,解除上游主机阻塞。然后重复Frame A相同处理过程。
需要强调的:
数据输入通道的AXI接口上的活动不一定与FFT内的活动相关。例如,在点A之前,信道加载帧B的样本数据,而FFT正在处理Frame A数据。
上游主模块不能不参考s_axis_data_tready信号,而一直输出数据流。
FFT在加载新帧之前,必须卸载转换完成的帧数据。

图13、倒序突发I/O模数时序
除了FFT配置为倒序输出,图13和图14是类似的。上游主模块一直输出数据,允许加载和卸载同时进行。
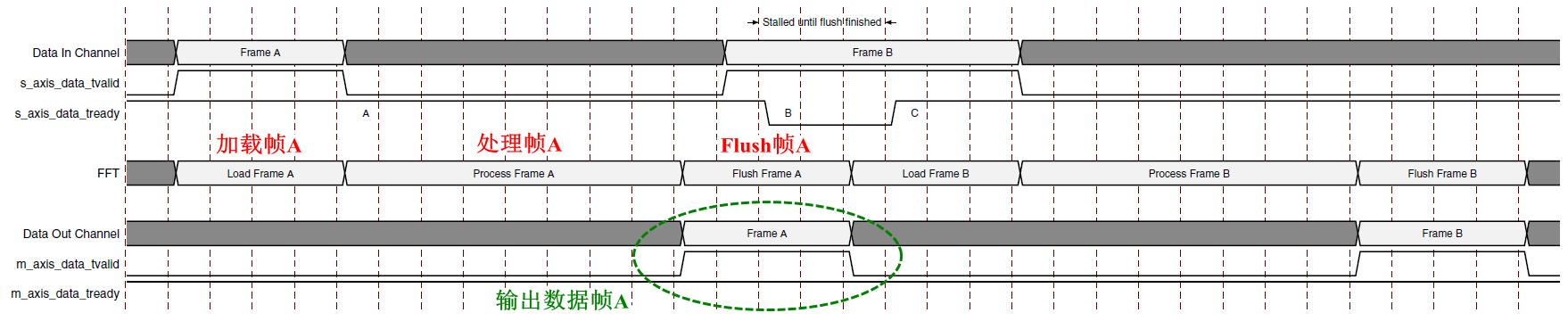
图14、倒序突发I/O模数时序(核Flushes帧)
除了上游主模块不会输出数据Frame B直到IP核开始刷新输出Frame A,图14和图13是类似的。在加载Frame B前,IP核必须先完成Frame A的刷新输出,加载和卸载不同同时进行。
图13和图14的时序区别在于两点:
加载和卸载是否可以同时进行处理;
数据输入通道上游主模块数据流加载是否一直处于加载状态。
9.小结
本文我们详细介绍了FFT/IFFT核操作的理论知识,内容较为详实,有些地方较为枯燥。有些内容通过实例讲解能够更好的理解;关于FFT架构的选择,我们要基于实际项目需要,比如转换时间是否满足实时处理要求,是否需要时分复用来节约资源等等,需要作出权衡;缩放因子如何计算及配置,在文中也给出了详细例子。