本文转载自: FPGA的现今未微信公众号
前面介绍了使用DDR时需要用到的一个功能MMU,与其紧密联系在一起的另一个功能就是链表。链表在通信相关的FPGA设计中有着非常重要的地位。本文重点介绍在FPGA设计中有关链表的方案以及一些难点。
普通链表
什么是链表?我们先看一个简单的问题,在一个数据块(block)中除了存放数据,还存放下一个数据块的地址,通过该地址将数据链在一起。如下图所示,这就是链表最常见的形式。

第一个数据块中存放的是data0和下一个数据块的地址addr1,addr1指向第二个数据块,第二个数据块存放的是data1和下一个数据块的地址addr2,以此类推,这就是一个最基本的单用户链表了。解决Hash冲突的链表方案就是这种方案。
那如果是多个用户,数据需要分用户缓存呢?每个用户都会有自己的链表,从而维护自己的数据结构,那就会变成下面的形式:

一共4个用户,每个用户分别存放各自的数据,每个用户都通过链表的形式把数据组织起来。这种存放的方式非常的简单,读取一个数据块中的数据后,就知道下一个数据在哪里。当data所代表的数据较大时,比如512byte甚至更大时,这种方案是完全可行的。但是当data所代表的数据较小,比如只有32byte的时候,采用这种方式来访问DDR,显然会影响访问DDR的性能(主要是GPS),因此需要对链表形式进行改进,减少读取DDR的次数。
压缩型链表
压缩性链表就是对普通链表的改进,当一个data比较小的时候,将多个data存放在一个数据块中,从而减少链表数,即减少对DDR的访问次数,提高访问性能。以2个用户为例,其链表结构如下图所示:
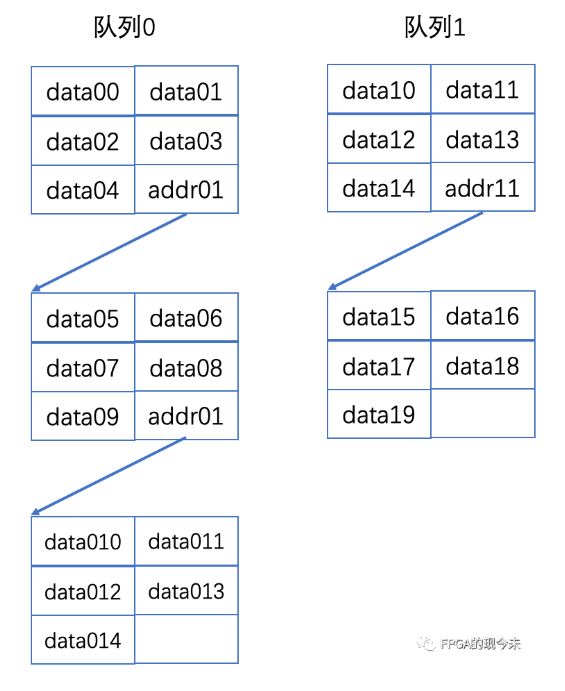
在一个数据块中,存放了5个数据,即操作一次DDR读出5个数据,相比普通链表,在相同的PPS下,该方案的性能提升5倍。每个数据块定多大,一个数据块中存放多少个data,都需要根据具体的应用场景,主要是性能场景来灵活选择。
虽然压缩型链表相比普通链表性能提升了,但是这2种方式都有2个弊病,(1)、链表地址必须有一个回写的过程,比如数据存入第二个块后,需要把第二个块的首地址回写到第一个块中,建立链表。这个回写的过程会影响数据的读写性能;(2)、读取数据的时候,必须先得到第一个块数据后,获取链表地址,才可以读下一个块数据,这种串行读取的方式也会影响数据的读取性能。如下图所示:

发送第一个读命令后,等到数据回来,再发送下一个读命令,每个读命令对应的数据之间有“缝隙”,不是最优性能。
数据地址分离链表
有一种改进方案就采用数据地址分离方式,即data和addr分开存放,去掉链表地址回写的操作。如下图所示:
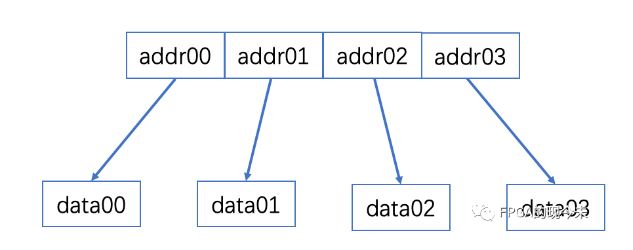
当地址和数据分离后,严格意义上来讲,已经不再是一种链表了。在这种方案中,写数据时不需要回写链表地址;读数据时,用户已经有4个地址了,可以采用背靠背的方式发送读命令,数据可以连续返回。如下图所示:

对于多用户的场景,每个用户需要单独的空间存放“链表地址”,假如每个用户最多申请128个数据块,也就是有128个地址,每个地址4byte,总容量为512byte,如果16个用户,则需要8kbyte的空间来存放所有的“链表地址”,这个空间用片上RAM就可以搞定。
考虑一种场景,当一个用户申请的数据块的个数是不确定的,即属于某个用户的“链表地址”非常非常多,多到片上放不下,怎么办呢?最简单直接的办法就是把链表也存放到DDR中,这就需要用链表把链表地址管理起来。
二级链表
所谓二级链表,就是将链表地址以链表的形式存放在DDR中,第一级链表为压缩型链表,第二级采用数据地址分离链表,如下图所示:
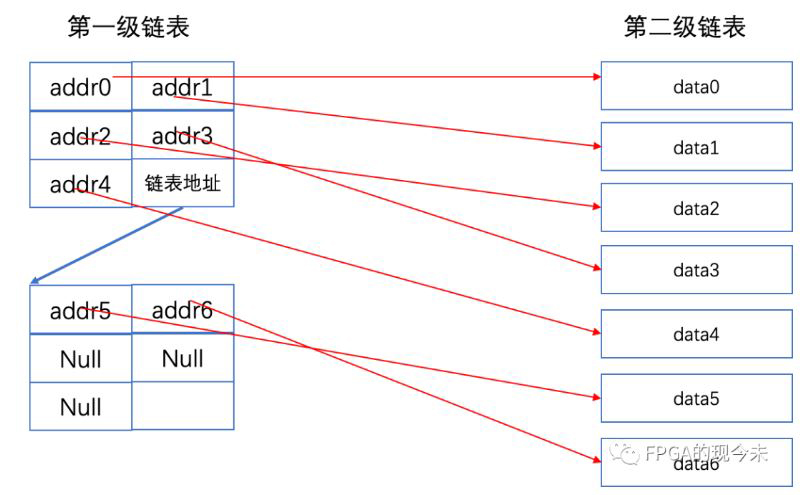
数据写入的过程大体分成如下几个步骤:
(1)数据写入DDR块中,同时在片内积攒对应的地址;
(2)当地址积攒到一定数量后,比如32个,打包写入DDR中;
(3)当地址再次积攒到32后,打包写入DDR中,同时建立链表;
(4)有新的数据需要写入时,重复上述步骤。
数据读出的时候过程分成如下几个步骤:
(1)读出第一级链表的链表地址块;
(2)根据链表地址块中的下一链地址,读取下一个链表地址块,同时,根本上次读取的链表地址块的地址,读取第二级链表中的数据。
(3)重复上述步骤,直到所有的链表地址块和数据块全部读完。
假如链表地址块中有32个地址,当读数据的时候,一次读取32个地址,然后可以连续发送32个读命令来读取数据,这样就可以形成背靠背的数据传输,达到最大带宽。
这种方案的难点就是计算出合理的第一级链表大小,地址太小,达不到背靠背传输的效果,地址太多,片上积攒地址的空间会增大,但是可以减少对DDR访问。
总结,链表的设计中,需要根据具体的应用场景,尤其是要评估好DDR的带宽是否满足需求后,采用上述的某种链表方案。如果对链表设计你有其他更好的方案,欢迎交流讨论。