本文转载自: OpenFPGA微信公众号
作为一名工程师,在项目实施阶段多多少少会遇到需要使用控制理论的应用程序。
一种非常常用的算法是比例积分微分控制器(proportional-integral-derivative control)或 PID 控制器。PID 算法用于控制各种应用中温度、压力、电机位置和流量等变量。我经常看到的一个地方是高端图像处理系统(制冷型红外),为了减少图像中的噪点。它使用热电冷却器或其他冷却系统来冷却图像传感器。对于高端成像,较低的噪声可以带来更好的图像。
介绍
PID 控制算法实现起来并不难,因为它只需要加法、乘法、除法和减法(dog)。但是,一旦算法实施,确保 PID 回路稳定的三个系数可能需要一点额外的时间来获取。
PID 主要使用三个术语。
每个术语还具有相关的增益 KI、KP 或 KD,可以帮助我们调整 PID 控制器算法的行为。D 项不是必须的,而且简单的情况下我们基本不使用,使用 PI 控制器也很常见。
PID经常使用浮点数来实现。因此,我们可以使用诸如 VHDL Fixed/Float 之类的库在 RTL 中实现。或者,我们可以使用HLS来实现 PID,因为国内应用VHDL较少,所以我们今天的实例是使用HLS构建我们的PID算法。使用HLS能够使用浮点或任意精度的定点数。HLS还能通过#pragma 快速的为IP添加通用控制接口(AXI)。
在纯 FPGA 实现类似系统时候,我们需要添加软核来控制IP。在较小的 Zynq-7000 SoC FPGA(7007、7010、7020 等)中则可以通过硬核控制IP。或者,如果我们设计中不想使用处理器,那我们可以设计传统的矢量接口即可。
源码设计
PID 的实际源代码非常简单,如下所示。
#include "pid.h"
static data_type error_prev =0;
static data_type i_prev=0;
data_type PID (data_type set_point, data_type KP, data_type KI, data_type KD, data_type sample, data_type ts, data_type pmax)
{
#pragma HLS INTERFACE mode=s_axilite port=return
#pragma HLS INTERFACE mode=s_axilite port=sample
#pragma HLS INTERFACE mode=s_axilite port=KD
#pragma HLS INTERFACE mode=s_axilite port=KI
#pragma HLS INTERFACE mode=s_axilite port=KP
#pragma HLS INTERFACE mode=s_axilite port=set_point
#pragma HLS INTERFACE mode=s_axilite port=ts
#pragma HLS INTERFACE mode=s_axilite port=pmax
data_type error, i, d, p;
data_type temp;
data_type op;
error = set_point - sample;
p = error * KP;
i = i_prev + (error * ts * KI);
d = KD * ((error - error_prev) / ts);
op = p+i+d;
error_prev = error;
if (op > pmax) {
i_prev = i_prev;
op = pmax;
}else{
i_prev = i;
}
return op;
}
已将previous error和previous integral声明为全局静态变量,以确保它们在迭代时候其值保持不变。
在算法方面,用户可以在应用程序运行时动态加载 KP、KI、KID、Ts 和 Pmax。我们可以轻松地添加积分值或使用附加寄存器重新启动控制器。这将使 PID 可以用于多个实现。
为了测试和配置 PID,测试文件罗列了一系列温度值,这些温度都远高于预期的目标设定点,并确保达到设定点。此示例中的 PID 设计用于提供功率(以瓦特为单位)维持光学床的温度。在这种情况下,我们需要加热而不是降低温度。
#include "pid.h"
#include
#define iterations 40
int main(void)
{
data_type set_point = -80.0;
data_type sample[iterations] = {-90.000,-88.988,-87.977,-86.966,-85.955,-84.946,-83.936,-82.928,-81.920,-80.912,-80.283,-79.926,-79.784,-79.774,-79.829,-79.898,-79.955,-79.993,-80.011,-80.017,-80.016,-80.010,-80.005,-80.002,-80.000,-79.999,-79.999,-79.999,-79.999,-80.000,-80.000,-80.000,-80.000,-80.000,-80.000,-80.000,-79.999,-80.000,-80.001,-80.000};
data_type kp = 19.6827; // w/k
data_type ki = 0.7420; // w/k/s
data_type kd = 0.0;
data_type op;
printf("testing cpp\r\n");
for (int i =0; i
printf("result %f\r\n",op);
}
return 0;
}
在 Vitis HLS 中针对该 PID 算法进行C 仿真和协同仿真,结果完全符合预期。

算法按照预期运行,下一步是综合和导出 IP,最后就是添加到我们的 Vivado 项目中。这次我们使用的是ZYNQ FPGA。

延迟性能和资源消耗
下面的完整框图反映了添加到Vivado项目中情况。

框图
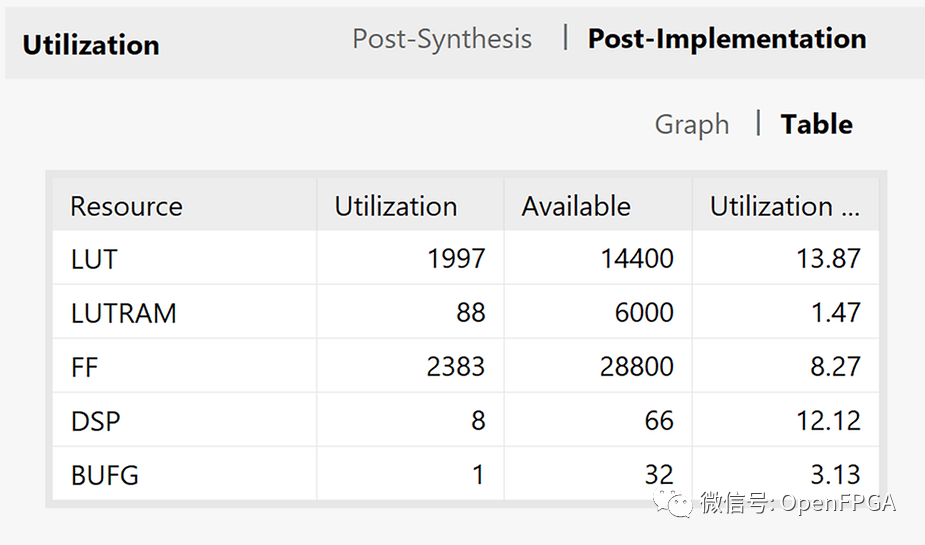
总设计资源

PID 资源
构建完成上面的Vivado项目,接下来就是导出硬件(XSA)到 Vitis 中开发驱动。
在 Vitis 中开发驱动时候,我重用了 HLS 仿真文件中的几个元素。
由于我们使用的是 AXI 接口,Vitis HLS 在导出IP时候地为我们提供了一个可以在 Vitis 中用于驱动 IP 核的驱动程序。但是,当在 IP 内核中使用浮点输入时,驱动程序则期望它们为 U32。如果我们在开发驱动时候从浮点数转换为 U32,我们将失去准确性。因此,解决这个问题的方法是使用指针(pointers)和强制转换。

本质上,我们将变量声明为浮点数,然后在函数中调用设置一个指向浮点变量地址的 U32 指针,并使用间接运算符读取该值。
XPid_Set_set_point ( & pid , * ( ( u32 * ) & set_point ) ) ;
整个应用程序是
#include
#include "platform.h"
#include "xil_printf.h"
#include "xpid.h"
#define iterations 40
typedef float data_type;
data_type set_point = -80.0;
data_type sample[iterations] = {-90.000,-88.988,-87.977,-86.966,-85.955,-84.946,-83.936,-82.928,-81.920,-80.912,-80.283,-79.926,-79.784,-79.774,-79.829,-79.898,-79.955,-79.993,-80.011,-80.017,-80.016,-80.010,-80.005,-80.002,-80.000,-79.999,-79.999,-79.999,-79.999,-80.000,-80.000,-80.000,-80.000,-80.000,-80.000,-80.000,-79.999,-80.000,-80.001,-80.000};
data_type kp = 19.6827; // w/k
data_type ki = 0.7420; // w/k/s
data_type kd = 0.0;
data_type ts = 12.5;
data_type pmax = 40;
u32 op;
XPid pid;
int main()
{
float result;
init_platform();
disable_caches();
print("Adiuvo PID Example\n\r");
XPid_Initialize(&pid,XPAR_XPID_0_DEVICE_ID);
XPid_Set_set_point(&pid, *((u32*)&set_point ));
XPid_Set_KP(&pid, *((u32*)&kp));
XPid_Set_KI(&pid, *((u32*)&ki));
XPid_Set_KD(&pid, *((u32*)&kd));
XPid_Set_ts(&pid, *((u32*)&ts));
XPid_Set_pmax(&pid, *((u32*)&pmax));
u32 tst = XPid_Get_set_point(&pid);
for (int i =0; i
XPid_Start(&pid);
while(!XPid_IsDone(&pid)){
}
op= XPid_Get_return(&pid);
result = *((float*)&op);
printf("result %f \r\n",result);
}
cleanup_platform();
etrurn 0;
}
运行,得到以下结果。

正如预期的那样,硬件中的实现与软件的工作方式相同。
当然,对于不同的应用程序,我们需要重新确定可用于应用程序的 KP、KI 和 KD 变量。
这样做的真正美妙之处在于,因为它是用 C 实现的,可维护性高,可以快速构建一个我们需要的PID算法。
完整项目在下面链接里。
参考
https://www.cnki.com.cn/Article/CJFDTOTAL-CAIZ201316188.htm
https://www.adiuvoengineering.com/
总结
虽然上面的流程很简单,但是HLS在调整资源和速度方面还是需要一些时间,并且浪费的资源还是比纯HDL多。
最后在说一下该方式的缺点,PID需要进行浮点运算,而FPGA则不能进行浮点运算,如果想把上面的算法在逻辑中运行,则需要自己进行量化,但是如果像上面例程的方式在内核(硬核)中运行算法,则该方式简单且优雅~
示例工程