DPU 是什么?
Xilinx® 深度学习处理器单元(DPU)是专用于卷积神经的可配置计算引擎网络。引擎中使用的并行度是设计参数,可以根据需要选择目标设备和应用程序。它包含一组高度优化的指令,并支持大多数卷积神经网络,例如 VGG、ResNet、GoogLeNet、YOLO、SSD、MobileNet、FPN 等,可将 DPU IP 作为一个模块集成到所选 Zynq®-7000 SoC 和 Zynq UltraScale™+ MPSoC 器件的可编程逻辑(PL)中,这些器件与处理系统(PS)直接相连。
AI 开发的新选择
米尔科技 MYD-CZU3EG
MYD-CZU3EG 开发板在原产品的基础上搭载了赛灵思深度学习处理单元 DPU,该部分新功能的增加可以极大的提升产品数据处理与运行效率,结合 DNNDK 工具链,AI 开发者就能用上赛灵思之前发布的算法资源,为 AI 应用落地提供完整支撑,帮助用户实现更为快速的产品开发和迭代。

适用领域
搭载 DPU 后,MYD-CZU3EG 可用于 ADAS,智能安防,工业质检,智能零售等诸多 AI 应用开发。
DNNK 应用开发流程
DNNDK 是一个工具套件,专门设计用于将深度神经网络(DNN)高效高效地部署到 Xilinx FPGA 平台,由量化器、编译器、汇编器、链接器和其他有用的实用程序(例如,探查器,模拟器和运行时库)组成,以提高使用 Xilinx 嵌入式平台开发 DNN 应用程序的效率。下图为 DNNDK 的系统框图(DNNDK 的安装及使用教程可参考 UG1327):

编译程序
DNNDK 编译流程如下图所示:
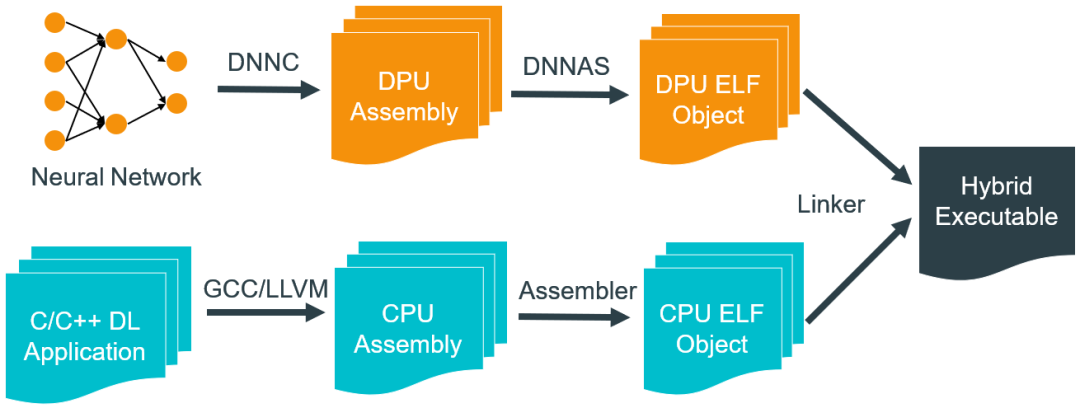
下面以 Caffe 模型 -restnet50 为例
列举使用 DNNDK 开发应用的流程:
1.压缩模型
a.拷贝资料
从资料包中拷贝 dnndk 文件夹到安装了 DNNDK 的服务器上,输入模型是浮点型的:float.caffemodel。确保在 float.prototxt 中填写的校准数据集的路径是正确的:

b.量化模型
使用 DECENT 工具量化模型,确保 decen.sh 脚本中对输入和输出的配置是正确的,如下图所示:
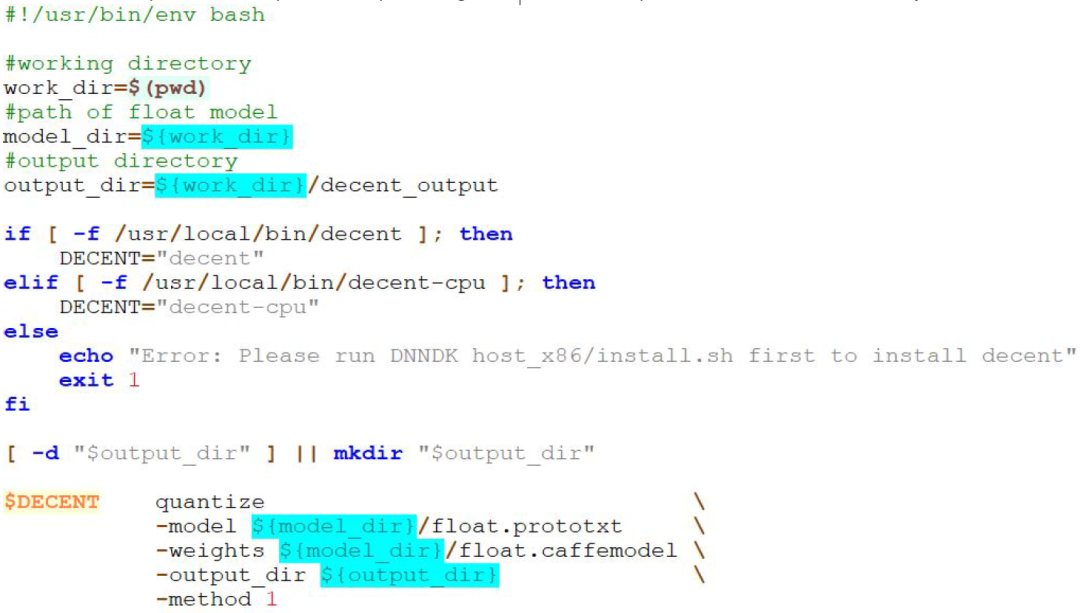
确保配置无误后执行脚本:sh decent.sh
运行后等待一段时间会输出以下信息即表示量化完成:

2.编译模型
a.生成 DNNC 工具所需的 .dcf 文件
dlet -f design.hwh
b.使用 DNNC 工具编译模型
sh dnnc_myir.sh
等待一段时间后会输出编译成功的信息:

由于我们使用 c++ 进行部署,所以不需要将 dpu_resnet50_0.elf 转换为 python 使用的 .so 文件。使用 dpu_resnet50_0.elf 和需要部署功能的 main.c 文件即可在开发板上生成可执行文件。
MYD-CZU3EG DPU 使用手册:http://www.myir-tech.com/download.asp?nid=93
开发板卡购买咨询可点击链接: http://www.myir-tech.com/product/myc-czu3eg.htm
文章来源:Xilinx赛灵思官微