本文转载自:cnBeta.COM
作为自适应计算领域的领导者,赛灵思(Xilinx)公司在 SC21 超算大会上推出了 Alveo U55C 数据中心加速卡,以及一套基于标准 API 驱动、用于大规模 FPGA 部署的新集群解决方案。前者能够为高性能计算(HPC)和数据库工作负载带来卓越的每瓦性能,并通过该公司的 HPC 集群解决方案实现轻松扩展。

来自:Xilinx 官网
Xilinx 表示,作为该公司迄今为止最强大的 Alveo 加速卡产品线,U55C 专为 HPC 和大数据工作负载打造,在其产品组合中提供了最高的计算密度和高带宽内存(HBM)容量。
结合基于 Xilinx RoCE v2 的新集群解决方案,拥有大规模计算工作负载的广大客户,现可利用其已有的数据中心基础设施和网络,构建基于 FPGA 的更强大 HPC 集群。

Xilinx 数据中心事业部执行副总裁兼总经理 Salil Raje 表示:扩展的 Alveo 计算能力,已较以往任何时候都更加容易、高效和强大。
从架构层面来讲,类似 Alveo 的 FPGA 加速卡能够以最低成本、为诸多计算密集型工作负载提供最高性能。
通过引入一种基于标准方法、允许客户使用现有基础设施和网络构建的 Alveo HPC 集群,Xilinx 重新为任何规模的数据中心提供了这些关键优势,同时也是在整个数据中心更广泛地采用 Alveo 和自适应计算的重大飞跃。

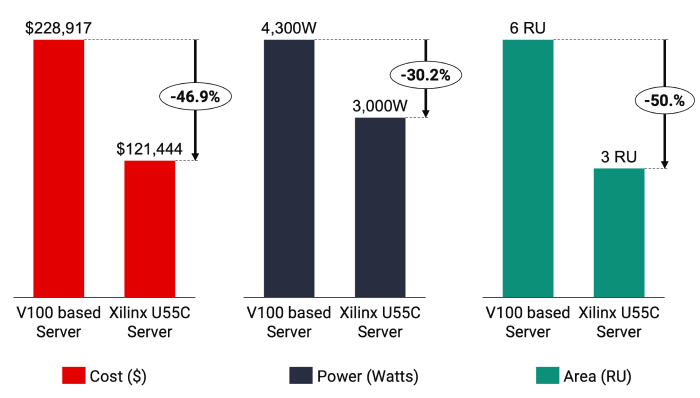
功能特性方面,Alveo U55C 加速卡结合了当今 HPC 工作负载所需的许多关键功能,包括更高的数据管道并行性、卓越的内存管理、优化的全管道数据移动、以及 Alveo 产品组合中最高的每瓦性能。
外形方面,其采用了单槽全高半长(FHHL)的设计,最大功率仅 150W 。而上代 U280 产品为双槽设计,不仅计算密度没有 U55C 高,HBM 缓存也只有 16GB 的一半。
对于想要打造基于 Alveo 加速器密集集群的数据中心客户来说,U55C 能够以更小外形提供更多算力,比如需要横向扩展的高密度流数据、高 IO 算数、以及解决大数据分析和 AI 应用程序等大型计算问题。
通过 RoCE v2 与数据中心桥接,在加上 200 Gbps 的带宽,API 驱动的集群解决方案使 Alveo 网络能够在性能和延迟方面与 InfiniBand 展开竞争,而没有被供应商套牢的顾虑。
此外 MPI 集成允许 HPC 开发人员从 Xilinx Vitis 统一软件平台扩展 Alveo 数据流水线(横跨数百张 Alveo 扩展卡),并利用现成的开放标准和框架,而无需烦心于服务器平台 / 网络基础设施、以及共享工作的负载和内存资源。
软件开发人员和数据科学家们,可以利用 Vitis 平台应用程序和集群的高级可编程特性,来充分释放 Alveo 和自适应计算的优势。
支持 Pytorch、Tensorflow 等主要 AI 框架,C、C++、Python 等高级编程语言,以及允许开发人员使用特定的 API 和库来构建特定领域的解决方案。
或者可以利用 Xilinx 的软件开发套件,来轻松加速数据中心内的现有关键 HPC 工作负载。

以澳大利亚 CSIRO 研究组织为例,其正在利用 Alveo U55C 为“平方公里阵列射电望远镜”的信号分析处理提供助力,这套系统使得 CSIRO 能够实时聚合、过滤、准备和处理来自 13.1 万根天线的大规模计算任务。
信号处理集群中的 460 Gbps HBM2 带宽,由 420 块 Alveo U55C 加速卡提供服务,后者通过支持 P4 的十万兆(100 Gbps)交换机完全联网在一起,整个集群的总吞吐量为 15 Tbps,兼顾了紧凑空间与成本效益。