作者:上海交通大学密西根学院王润曦、顾宇琪、郭鑫斐,文章来源: XILINX开发者社区
摘要
本项目对于目前全球新冠疫情下低收入国家疫苗接种率不高的问题,运用AMD-Xilinx提供的KV260硬件平台和Vitis-AI开发平台,基于2D图像的视觉AI辅助的疫苗肌肉注射点检测技术,结合轻量级神经网络模型,利用量化技术、后处理技术等,设计了一个低开发成本、低人力成本、低交叉感染风险的自动疫苗接种方案。

项目背景
新型冠状病毒还在影响着人们生活的方方面面,给公共卫生、全球运输系统和许多领域带来了前所未有的挑战。大多数政府已经实施过封锁,限制国际旅行等各类政策,以减轻病毒的传播。鉴于目前还没有能够对抗病毒的特效药,接种疫苗仍然是最有效手段之一。
然而,全球疫苗接种率仍然很低,尤其是在低收入国家。根据世卫组织的数据,低收入国家只有14.5%的人口接种了至少一剂疫苗[1]。许多非洲国家的疫苗接种率更低,仅在1.5%至4%之间。在这种情况下,如何才能提供一个低成本的疫苗接种方案是最紧急,但也是极具挑战性的。因为开发疫苗本身成本很高,接种疫苗这个过程也有一定成本,此外,传统的疫苗接种可能会增加病毒传播的风险,还有医护人员的工作量。
自主机器人注射能成为一种安全有效的方案,人们只需走进封闭的空间,露出手臂。最近,有两个自动注射机器人原型被开发出来。第一个是加拿大的初创公司开发的Cobi:是世界上第一个自动无针注射机器人,它通过激光雷达传感器和AI位置跟踪,得以识别人体识别。然后, 360度深度感知系统会引导机械臂定位,注射药物[2]。另外一个是“后羿”,它是由上海同济大学研发的国内首款自动疫苗注射机器人,它通过三维人体模型,得以自动识别注射位置。通过一个简单的三维点云相机对人体进行拍摄,快速自动拟合人体对应部位的三维模型,准确识别疫苗注射部位及注射角度。[3, 4]

值得一提的是,这两种解决方案都采用了无针注射,确保了安全和无痛注射。另一个关键因素是它们检测注射部位的方案。为了完成检测任务,这两种机器人的方案都涉及到复杂的三维模型识别算法还有多维度的传感器。虽然这两个机器人所用的算法可以提供准确的部位检测,但它们也涉及大量的开发工作,多维度传感技术和昂贵的硬件支持,这些都会增加这些机器人的整体成本。所以本项目中,我们认为有必要去提出一个低成本且有效的注射点识别方案,这样才将机器人部署到世界各地。
在正式开始项目之前,我们咨询医学专家得知目前的新冠疫苗主要是靠肌肉注射,因为可以使药剂迅速参与到系统循环中。综合考虑下,三角肌是最适合接种的部位,因为它血供充足,面积大。而且不同个体之间,三角肌差异不大。这启发了我们,基于Xilinx KV260,利用视觉AI辅助技术,实现2D肌内注射部位检测方案。
技术设计过程总览

我们的目标是让连接 KV260 的显示器指示患者手臂上的注射部位。由于硬件资源的限制和目前现有的手臂检测工作数量较少,我们决定将问题简化为人脸检测辅助后处理来指示结果。对于我们项目的主体部分,研究重点放在基于 Vitis-AI 的模型选择和训练策略。而对于后处理,主要使用OpenCV进行代码编写,后使用VVAS进行编译和处理。在测试阶段,我们使用收集到的与我们的应用场景相匹配的图片来查看模型与后处理模块结合下的准确性,然后相应地调整我们的模型或是后处理模块的参数。
基于Vitis-AI的模型准备
根据VVAS官网的描述,VVAS支持 Vitis-AI 模型是有限的,对于我们需要的模型类 FACEDETECT,VVAS 中只有 densebox 可用,并且精度在我们可以接受的范围内。考虑到我们的应用场景是疫苗接种。为了降低病毒传播的风险,人们在打针时大多戴口罩。Vitis-AI 中预训练使用的数据集为 WIDER FACE,该数据集内不强调佩戴医用口罩的人脸。为了确保可以很好地检测戴口罩的人脸,尤其是当人们在注射过程中将侧脸转向仪器时,我们使用 MAFA(一个有口罩人脸数据集)对densebox原先自带的预训练的结果进行增加性训练。
模型训练、量化与编译流程
我们采用Vitis-AI里面预置的Caffe框架,可以使用以下命令在Vitis-AI中启动它:

我们的训练是基于Vitis-AI中预训练结果进行的,可以访问Vitis-AI的官方repo下载需要的densebox模型相关文件,并执行以下命令:

当然,在执行以上命令之前,请记得将“train.prototxt”文件中指向数据集的path改为MAFA数据集所在的路径。
对于模型的量化,我们只需执行以下命令:

该命令中使用到的“.caffemodel”浮点模型文件可由上一步的训练命令执行后得到,也可从我们整个项目的repo中下载:
https://github.com/iCAS-SJTU/J-eye/tree/main/models/float
为了得到最后能在KV260上执行的模型文件“.xmodel”,我们需要对量化后模型文件进行编译,可采用以下命令:

该命令中使用的文件均可从https://github.com/iCAS-SJTU/J-eye/tree/main/models/quantized下载,其中两个“deploy.*”文件均为模型量化后结果,“arch.json”文件可由KV260的官方源码repo获得。
后处理模块搭建
后处理模块的搭建中主要运用的工具就是VVAS,我们需要将它的整个repo clone下来。

(该部分的过程都假定我们在“${PATH_TO_VVAS}/VVAS/”目录底下,关于交叉编译环境的搭建,由于篇幅原因,详见我们在hackster.io上发布的文章)。
首先,我们需要先编译vvas-util里面的文件。这之中的第一步需要我们修改“meson.cross”里面的“SYSROOT”和“NATIVESYSROOT”。接着我们在“vvas-utils/”这个目录下执行以下命令:

在成功编译之后,将以下文件复制到指定位置。

同时也可以把“vvas-utils/”目录下的所有“.h”文件复制到“${SYSROOT}/usr/include”这个目录下以避免一些后续的报错。
结束了“vvas-utils”部分的编译之后,我们开始“vvas-gst-plugins”部分的处理。我们可以再利用前面编辑过的“meson.cross”文件(直接复制到“vvas-gst-plugins/”目录下),然后执行同样的编译命令。

成功编译之后,我们还需要做一些文件复制。

同时也同样需要把“vvas-gst-plugins/”目录下的所有“.h”文件复制到“${SYSROOT}/usr/include”这个目录下以避免一些后续的报错。
最后一步,我们进入到“vvas-accel-sw-libs/”目录下,将其中“vvas_xboundingbox/src”下的“vvas_xboundingbox.cpp”替换成我们修改过的https://github.com/iCAS-SJTU/J-eye/tree/main/post-processing/src中的cpp代码。然后执行以下命令:

在编译成功之后,进入到“build/vvas_xboundingbox/”下我们可以找到”vvas_xboundingbox.so”文件用于后处理模块当中。
集成于KV260
由于我们的应用是基于smartcam的,我们需要先下载基本的smartcam应用包。

在/opt/xilinx/share/ivas/smartcam/目录下,执行以下命令。

接着,将
https://github.com/iCAS-SJTU/J-eye/tree/main/models/compiled
中所有的文件下载到该目录中。我们还需要将后处理模块要用到的文件
https://github.com/iCAS-SJTU/J-eye/tree/main/post-processing
复制到/opt/xilinx/lib目录底下。文件都部署完成后,我们可以执行以下命令来运行整个程序。

结果演示
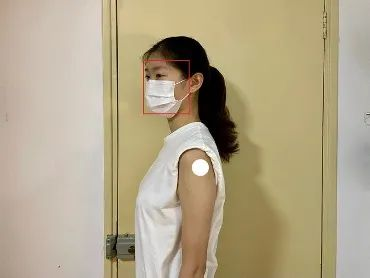
患者应面朝左侧直立站/坐于相机前,检测结果将呈现于下图中显示器。

当患者位于难以进行注射的位置时,显示器上将发出位置偏离的警告信息。

当患者位于可检测范围内时,注射点位置将由白色圆圈标出。
参考资料
[1] https://www.cnbc.com/2022/02/02/these-countries-have-the-lowest-covid-va...
[2] https://www.inceptivemind.com/cobi-robot-autonomously-performs-intramusc...
[3] https://www.globaltimes.cn/page/202201/1246148.shtml
[4] https://inf.news/en/tech/1fe00617cfdae9eda4464a2b42006525.html
[5] https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7886662/
[6] https://www.eet-china.com/mp/a86386.html
[7] https://www.xilinx.com/support/documentation/sw_manuals/vitis_ai/1_3/ug1...
[8] https://xilinx.github.io/kria-apps-docs/main/build/html/docs/smartcamera...