本文作者:达坦科技DatenLord 翁万正
概要
该项目基于AMD Xilinx Varium C1100 FPGA加速卡,为 Filecoin 区块链应用中的Poseidon哈希算法提供了一套完整的硬件加速方案。在硬件方面,使用SpinalHDL 设计了Poseidon加速器模块并基于Vivado Block Design 工具搭建完整的FPGA硬件系统。在软件方面,该项目为 Filecoin 软件实现 Lotus 提供了访问 FPGA 硬件加速器的接口。最终,整个项目能为Filecoin中Poseidon哈希函数的计算带来两倍于AMD Ryzen 5900X处理器的性能提升。
1. 项目背景
1.1 零知识证明与Poseidon
Poseidon是一种全新的面向零知识证明(ZKP: Zero-Knowledge Proof)密码学协议设计的哈希算法。相比同类算法,包括经典的SHA-256、SHA-3以及Pedersen哈希函数,Poseidon最大的特点和优势在于其针对零知识证明协议做了特定优化,够显著降低证明生成的计算复杂度。
零知识证明是一类用于验证计算完整性(Computational Integrity)的密码学协议。其基本的思想是: 使证明者(Prover)能够在不泄露任何有效信息的情况下向验证者(Verifier)证明某个计算等式的成立。由于能够兼顾隐私保护和计算完整性证明,零知识证明具备广泛的应用场景,也是目前密码学、区块链以及可信计算方向上的研究热点之一。其具体的应用场景包括: 匿名线上拍卖、云数据库SQL查询验证、去中心化数据存储系统等。尤其是在区块链和加密货币领域,零知识证明凭借其出色的隐私保护特性, 近年来获得了大量开发者和设计者的青睐, 包括加密货币Zcash和Pinocchio以及分布式存储系统Filecoin等在其设计中都采用了ZK-SNARK零知识证明算法。
虽然零知识证明能在提供计算完整性验证的同时兼顾隐私的保护, 但其代价是提高了证明生成和验证的计算复杂度,这在一定程度上阻碍了其在实际项目中获得更加广泛的应用。目前,加速零知识证明的途径主要有两种,一方面是通过设计专用的硬件电路或者GPU来加速证明算法中的计算瓶颈;另一方面,可以通过优化证明对象,使待证函数更加适配于证明算法进而减少证明生成过程的计算复杂度。例如,当Poseidon哈希算法和SHA-256算法同时作为ZK-SNARK的证明对象时,Poseidon所需的证明生成的计算量要显著小于SHA-256。
1.2 Filecoin分布式存储网络
该项目实现的Poseidon加速器主要针对的是应用在Filecoin分布式存储网络中的Poseidon哈希计算实例。Filecoin是基于区块链技术建立的一种去中心化、分布式、开源的云存储网络。其在提供存储服务的过程中需要对数据进行Poseidon哈希运算,这一计算过程需要消耗大量的算力,是整个Filecoin系统运行的性能瓶颈之一。
目前,应用最为广泛的Filecoin软件实现是由Protocol Labs基于Go语言编写的Lotus。可以将Lotus理解为用户与整个Filecoin存储网络进行交互的接口。该项目在Poseidon加速电路的基础上,为Lotus提供了访问底层FPGA硬件加速器的软件接口,同时通过Lotus-Bench对FPGA的加速性能进行了测试和比较。
2. Poseidon哈希算法概述
Poseidon哈希函数的计算流程大致如下图所示,从输入和输出的角度看,Poseidon哈希函数将输入的t个有限域元素组成的向量映射到一个输出有限域元素。对于本次课题加速的Filecoin Poseidon实例,t的取值可以是3、5、9或12,同时每个元素的位宽为255 Bit。具体的计算过程由RF次Full Round循环和RP 次Partial Round循环组成。每次循环迭代都需要依次完成Add Round Constants常数模加、S-Box五次方模幂和MDS Mixing向量-矩阵模乘三个阶段的计算。

基于上述算法流程的介绍,Poseidon哈希函数硬件加速的难点主要分为三个层面:
a.基本运算单元: Poseidon哈希函数的基本运算单元包括模加和模乘。电路实现上模运算中的取余操作需要更加复杂的结构,同时操作数高位宽的特点也给电路设计提出了很大的挑战;
b.向量-矩阵乘法模块: Poseidon中需要完成最高宽度为12的向量-矩阵乘法,其中涉及大量的乘加运算,是整个函数计算的性能瓶颈之一;
c.整体电路架构: Poseidon哈希函数的计算需要完成(RF+RP)次的循环迭代,而由于FPGA硬件资源的限制,无法将所有的循环在电路上展开得到一个全流水线的架构,需要设计额外的电路结构实现计算资源的复用。
3. 基于SpinalHDL和Cocotb的电路设计与验证
本次项目中采用了基于Scala的硬件生成器语言 SpinaHDL和基于Python的验证框架Cocotb完成Poseidon 加速器IP的设计与验证。这两种新兴的设计和验证工具极大提升了硬件开发的效率和质量。
3.1 SpinalHDL硬件描述语言
和RISC-V处理器开发中常用的Chisel类似,SpinalHDL是一种基于高级编程语言Scala的硬件生成器语言HCL(HCL: Hardware Construction Language)。基于SpinalHDL的硬件开发流程:首先需要使用Scala以及SpinalHDL中提供的电路单元描述整体的电路结构,然后编译运行Scala代码生成对应的Verilog程序,并在Verilog代码的基础上完成仿真、调试以及综合等流程。
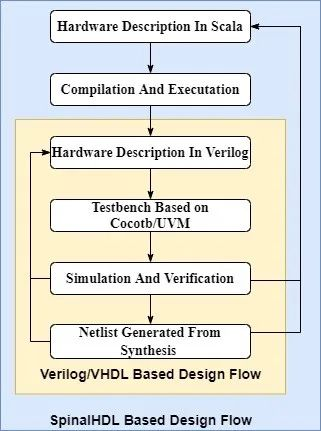
SpinalHDL提升硬件设计效率主要分成两个方面:首先,Spinal建立在Scala高级编程语言的基础上,因此能够使用Scala中各种高级的编程特性提升电路描述的能力,具体包括:
a.面向对象编程:Scala中面向对象的编程特性给硬件电路设计带来了更强的参数化能力,极大提升代码的复用性。例如,在本次项目中我们为Poseidon加速器设计了一个配置类,这个配置类中包含了数据位宽、输入向量宽度等,通过修改配置类的参数,能够高效地将本项目中实现的Filecoin Poseidon加速电路适配到其他的应用中。

b.递归:很大一部分电路的结构都具备递归的特点,如果使用递归的编程特性进行电路描述能够极大地提升开发效率,同时提升代码的复用性。
c.函数式编程:函数式编程是基于变量之间的映射关系来对系统进行建模,相比常用的面向过程的编程方式,函数式编程更加符合电路并行的特点。
在Scala的基础上,SpinalHDL在硬件开发上的优势包括:
a.和Verilog相同的电路描述粒度:和同样基于高级编程语言进行电路描述的高层次综合工具HLS不同,Spinal仍然是在结构层面对电路进行建模,同时其具备和Verilog相同的电路描述粒度,如下表所示,所有Verilog可综合的语法元素都能在SpinalHDL中找到相对应的部分:

b.丰富的电路元件抽象: SpinalHDL为硬件设计提供了丰富的电路元件抽象,例如状态机、计数器以及总线控制器等,能够使开发者避免重复实现底层的基础模块进而从更高的层次构建电路;
c.更加可靠的电路描述方式:首先,SpinalHDL为电路设计提供了更加准确的描述模型,例如,Verilog中只能使用wire描述信号,而Spinal提供了包括UInt(无符号整数)、SInt(有符号整数)、Bits(比特信号)等更加精确的描述模型。在此基础上,SpinalHDL在编译生成Verilog代码的过程中会对电路描述进行相应的设计规则检查,包括: Bits信号不能用于算术运算、信号连接时的位宽匹配、误用锁存器等问题。
3.2 Cocotb验证框架
Cocotb是一种开源的基于Python的数字电路验证框架,该验证框架的具体工作模式如下图所示。开发者可以完全在Python环境中完成测试功能的代码实现,而Cocotb框架通过VPI接口与仿真器中的待测模型进行交互。目前Cocotb已经可以支持大部分的仿真器包括:Verilator、Synopsis VCS和Modelsim等。
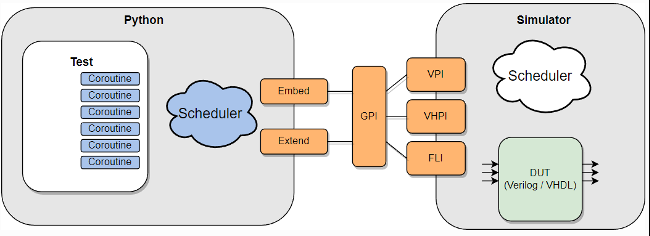
Cocotb在电路功能验证上的优势主要包括:
a.Python高效简洁的表达能力提升测试代码的编写效率;
b.复用Python丰富的生态搭建参考模型;
c.使用pytest、pytest-parallel、cocotb-test等软件测试框架对代码进行更加高效的管理。
4. 总体方案设计
加速系统的架构设计如下图所示。整个系统主要分为CPU服务器和FPGA加速卡两个主体。CPU服务器运行Filecoin的具体软件实现Lotus提供数据存储服务,当需要进行Poseidon哈希函数的计算时,服务器以DMA的方式将数据传输到Poseidon硬件加速器当中进行哈希计算。Poseidon加速器完成计算后以相同的方式将哈希结果传回处理器内存中。
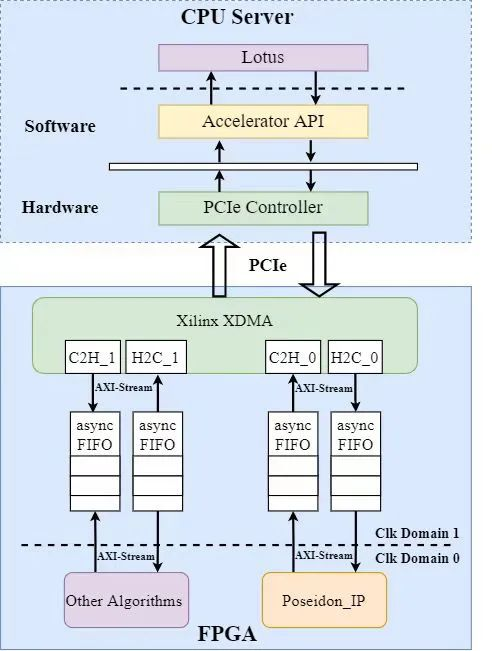
其中FPGA硬件系统主要由三个部分组成:
a.AMD Xilinx XDMA IP:实现数据从CPU内存到FPGA的搬运;同时负责PCIe外设总线到FPGA片内AXI-Stream总线的转换;
b.异步FIFO:XDMA输出总线的时钟频率固定为250MHz,而Poseidon加速器IP的工作频率在100-200MHz左右,异步FIFO实现了这两部分之间的跨时钟域数据传输;
c.Poseidon加速器:整个FPGA加速卡的核心部分,负责Poseidon哈希函数的计算加速。
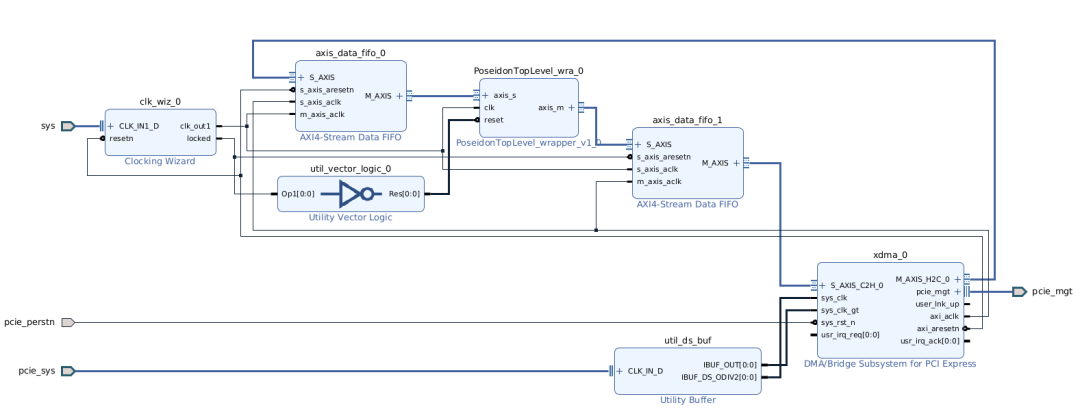
在上述系统架构设计的基础上,本次课题研究中实际搭建的FPGA硬件系统如下。和上图展示的硬件架构图相比,实际的FPGA硬件系统中增加了Utility、Buffer、Utility Vector Logic和Clock Wizard等模块来处理时钟和复位信号。
5. Poseidon加速器 IP 设计
在上述FPGA系统架构设计的基础上,这部分内容将介绍其中的核心模块Poseidon加速器IP的设计与实现细节。对于任意算法的硬件加速器,其设计与实现大体上都可以分成单元运算电路和整体硬件架构两部分。对于单元运算电路而言,诸如加法器、乘法器和模乘器等,其设计的主要目标是如何在更少的硬件开销下达到更佳的计算性能。在单元运算电路的基础上,硬件架构设计需要考虑的是如何提升每个运算单元的利用率,进而使加速器整体达到更高的数据吞吐率。本节将对Poseidon涉及的两种模运算,包括模加和模乘的具体电路实现以及加速器硬件架构的设计做详细地介绍。
5.1 模加电路的设计
任意模运算的实现都可以分成一次普通算术运算和取余运算两部分。对于模加,需要先完成一次普通加法,然后将加法结果缩减到模数所规定的范围内。最简单的取余方式可以通过一次比较判断和减法完成,具体如下公式所示:

该算法对应硬件电路结构如下图(a)所示, 具体数据通路为:输入操作数经过一个加法器后得到加法结果,将加法结果同时传递给减法器和比较器,分别得到减去模值和与模值比较的结果,将比较结果作为多路选择器的选通信号对加法器和减法器的输出进行仲裁后输出。

除了普通加法和减法操作相结合的方式外,还可以只通过两次普通加法实现相同的模加功能,具体的算法定义如下:

其对应的硬件电路结构由两个加法器和一个多路选择器组成,如上图(b)所示,具体数据通路为:输入操作数经过第一个加法器,输出两数之和与进位;两数之和继续输入第二个加法器,将两次加法的进位进行或运算后,作为多路选择器的选通信号对两次加法结果进行仲裁后输出。
上述两种模加的实现方式均需要两个加/减法器,分别完成加法和取余的计算步骤,然后经过一个多路选择器仲裁后输出,而第二种方法通过与门生成对应的选通信号,相比前一种方式能够节约一个比较器的电路开销。具体的实现中,由于Poseidon操作数位宽为255比特,在代码中直接实现单周期加法器会对整体的时序产生较大的影响。为了提高电路的工作频率,我们将图(b)中两个255比特加法器进行了全流水线化,每个加法器进行五级流水线的分割,并在多路选择器的输出端添加一级寄存器,使得整体模加电路总共包含11级流水延迟。流水线化后的模加电路结构如上图 (c) 所示。
5.2 模乘电路的设计
和模加电路类似,模乘的实现也可以分解成一次普通的乘法运算和取余两个步骤。这两个步骤分别对应模乘实现过程中的两个难点。
首先,从普通乘法的角度,Poseidon哈希函数操作数的位宽为255Bit。本项目中解决高位宽乘法的方式为: 将其分解成若干并行的小乘法器,而小乘法器通过调用FPGA中嵌入的DSP模块实现,具体的分解方式采用了Karatsuba-Offman算法,其算法定义如下公式所示:

上述算法对应的乘法器拆分结构如下图,每次拆分后乘法器位宽减半,但数量上增加两倍,同时需要引入额外的加/减法器。基于递归的思想,图中的三个乘法器还可以不断地进行拆分,直至位宽满足需求。本次项目中对255比特的乘法器进行了三次拆分,最终分解为27个并行的34-Bit乘法器。而34比特乘法器则通过调用AMD Xilinx提供的乘法器IP实现。
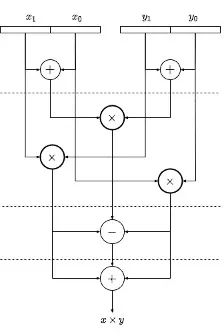
其次,从取余的角度,和模加中通过减/加法即可实现不同,模乘运算的取余通常需要在除法的基础上完成,而除法器需要复杂的电路结构同时会消耗大量逻辑资源,对于硬件实现不够友好。因此,大部分模乘电路的设计都采用了优化的取余方式,将除法转换成其他容易在硬件上实现的算术运算。本次项目基于Montgomery Reduction算法实现模乘器电路。Montgomery算法的基本思想是通过数域转换的方式,将操作数和运算结果转换到Montgomery域内,在该数域内取余计算中的除法可以简化成移位实现,具体的算法定义如下所示:

具体的电路实现结构如下图所示,其数据通路主要由三个级联的乘法器以及两个加法器组成。
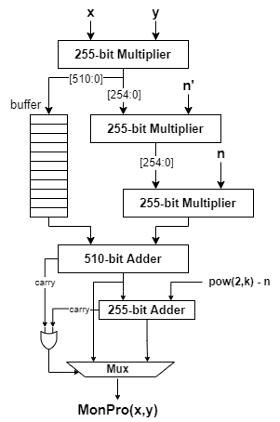
5.3 加速器架构设计
基于第二部分中算法流程的定义,项目中实现的Poseidon加速器的具体硬件架构如下图所示。在Poseidon单次迭代的算法流程的基础上, 加速器的实现针对具体的FPGA架构特点和硬件资源限制做了如下几点优化:
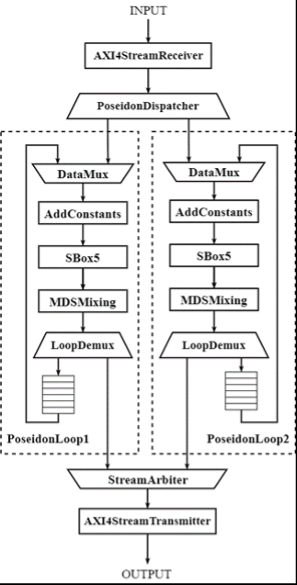
a.流水线处理:
为了提高加速器的工作频率,对Poseidon加速器的数据通路进行了流水线化的处理。数据通路主要由模乘和模加单元组成,而每个模运算单元的组合逻辑路径都进行了充分的切割,其中模加运算包含了11级流水,而Montgomery模乘器分割成了43级流水,整个计算通路总共由两百级左右的流水组成。
b.折叠的设计思路:
Poseidon哈希算法总共由(RF+RP)次迭代组成,对于Filecoin Poseidon实例,根据中间状态向量大小的不同,总共需要63 - 65次循环。由于FPGA硬件资源的限制,设计中不可能将所有循环都在电路上展开。因此需要基于折叠的思路,即时分复用的方式,在有限的循环单元上完成Poseidon哈希算法的所有迭代。具体的实现里,每个PoseidonLoop都可以完成一次Partial Round或Full Round的计算,而整个PoseidonLoop的数据通路呈环状结构,输入数据在环中不断的流动,直至所有迭代完成后输出。
c.并行计算:
Poseidon加速器IP中配置了两个相同的PoseidonLoop核心模块,并行地进行Poseidon哈希函数的计算。
基于上述架构设计,整个Poseidon加速器的工作流程主要可以分成三个阶段:
a.输入阶段: AXIStreamReceiver模块接收XDMA IP以AXI-Stream总线协议传送来的输入数据,并将其转换成加速器内部的数据传输格式。PoseidonDispatcher负责将AXIStreamReceiver输出的数据分发到两个迭代单元中。
b.计算阶段:输入数据在两个PoseidonLoop的环形数据通路中不断流动,直至所有循环完成后输出;
c.输出阶段:StreamArbiter对两个迭代模块PoseidonLoop的输出进行仲裁后传递给AXIStreamTransmitter模块,而AXIStreamTransmitter模块负责将内部数据传输格式转换成AXI4-Stream总线形式输出。
6. 性能测试
在上文中介绍的FPGA硬件系统和其中Poseidon加速器IP的基础上,我们通过Vivado集成开发环境将其实现在了Varium C1100 FPGA加速卡上,该板卡搭载了AMD Xilinx Virtex UltraScale+系列的FPGA芯片,具体芯片型号为具体型号为XCU55N-FSVH2892-2L-E。整个硬件系统实现(Implementation)后的报告以及性能测试结果如下:
6.1 Vivado Implementation 报告
整体硬件加速系统综合实现后逻辑资源消耗情况如下表所示:
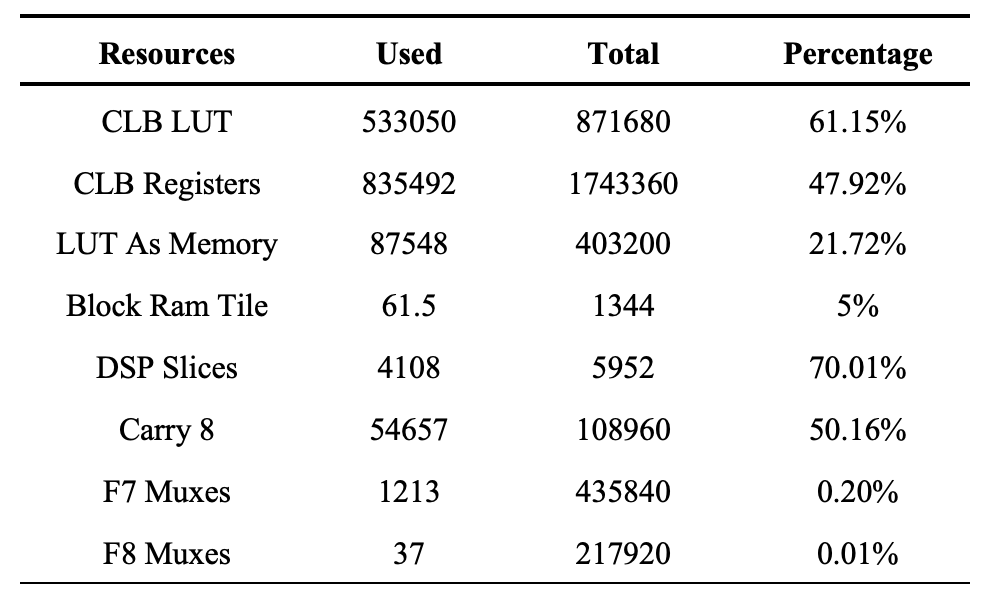
各项FPGA资源中DSP Slices(70.01%)和LUT(61.15%)的消耗最多, 主要用于255-Bit Montgomery模乘电路的实现上。这两项资源的不足也限制了在加速器中配置更多模乘器来提升计算并行度和整体的加速性能。
在时序上,实现(Implementation)后Poseidon加速器刚好能够满足100MHz工作频率的要求。关键路径上,建立(set up)时间的余量为0.069ns,保持(hold)时间的余量为0.01ns。
除了资源和时序外,FPGA实现后的功耗信息如下图所示。由下图可见,在运行我们设计的加速器硬件时,FPGA芯片的整体功耗在24.7W左右。而我们在性能测试中使用的RTX 3070 GPU加速卡的运行功耗在120W左右。

6.2 计算性能测试
a.吞吐率测试:在 AMD Xilinx提供的XDMA驱动的基础上项目中为加速器编写了简单的性能测试程序。该测试程序向FPGA加速器写入一定数量的输入数据,并记录加速器完成所有数据哈希运算所需要的时间。基于该测试程序,我们分别测试了Poseidon加速器在三种长度输入数据下的性能表现。当输入数据的大小为 arity2,加速器在0.877秒内完成了850000次的哈希运算,数据吞吐率可达到29.1651MB/s, 即每秒大约能够完成1M次哈希运算;

b.Lotus-Bench测试结果:Lotus中提供了计算机硬件在Filecoin计算负载下性能表现的基准测试程序Lotus-Bench;该测试更加接近实际的工作负载,能够得到更加准确的测试结果。在Lotus-Bench的基础上,我们分别测试了CPU, GPU和FPGA 在preCommit阶段(该阶段主要完成Poseidon哈希函数的计算)处理512MB数据所需要的时间。FPGA在 Lotus-Bench 测试下的算力可达到 15.65MB/s,大约是AMD Ryzen 5900X CPU实现的2倍,但和RTX 3070 GPU的加速性能相比仍有很大的提升空间。

总结
本项目为Filecoin区块链应用中的Poseidon哈希函数提供了基于FPGA的加速方案。硬件上,我们基于AMD Xilinx Varium C1100 FPGA板卡搭建了一个完整的加速系统,该系统主要由XDMA、FIFO以及Poseidon加速器IP三部分组成。其中,Poseidon加速器IP是整个系统的核心部分,其设计与实现主要可以分成单元运算电路和整体架构两个部分。在单元运算电路的实现中,我们基于Karatsuba-Offman算法将高位宽乘法分解成若干并行的小乘法器实现,同时采用Montgomery Reduction算法将取余过程中复杂的除法运算转换成乘法实现。在加速器架构的设计上,我们针对具体的FPGA硬件资源限制,基于流水线和折叠技术设计了一个串行的Poseidon计算架构。最终,FPGA加速系统能够工作在100MHz并为Filecoin提供两倍于AMD Ryzen 5900X处理器的加速性能。