文章来源:内容由半导体行业观察(ID:icbank)编译自semianalysis,谢谢。
由于 GPU 严重短缺,Nvidia 收取的费用是制造成本的 5 倍左右,业内每个人都迫切希望找到替代方案。虽然谷歌在 AI 工作负载方面具有结构性性能/TCO 优势,但由于其 TPU具有成熟的硬件和软件OCS,因此与其他大型科技公司相比,我们认为存在结构性问题会阻止他们成为外部使用的领导者。
1、谷歌 TPU 将只能从 1 个公司在 1 个云中获得。
2、谷歌Google 在芯片部署很久之后才会公开他们的芯片,因为大买家需要在发布前记录下来,并在 ramp 之前提供早期访问系统。
3、多年来,谷歌一直向用户隐藏多项主要硬件功能,包括内存/计算相关和网络/部署灵活性。
4、谷歌拒绝为那些想要编写自定义内核以最大化性能的奇才在外部提供低级别的硬件文档。
谷歌在 AI 基础设施方面的最大技术进步的守门人将使他们在结构上与基于 Nvidia 的云产品相比处于落后地位,除非谷歌改变他们的运作方式。来自亚马逊和微软等其他云的内部芯片仍然远远落后。
在商业芯片的世界里, Cerebras 目前是最接近的竞争对手,在 GPT-3 上表现稳定开源模型令人印象深刻,但硬件可访问性非常有限,每台服务器成本高达数百万美元。在云中访问 Cerebras 的唯一方法是通过他们自己的产品。缺乏访问权会损害开发的灵活性。Nvidia 生态系统的生命线是人们在各种各样的系统上进行开发,从他们花费数百美元的游戏 GPU 到最终能够扩展到拥有数万个本地 GPU 或与所有第 3 方云服务提供商合作. 而Tenstorrent 等其他初创公司则表现出希望我们认为硬件/软件距离真正大踏步前进还有一段距离。
尽管收购了两家不同的数据中心 AI 硬件公司 Nervana 和 Habana,但世界上最大的商用芯片供应商英特尔却不见踪影。Nervana几年前就被抛弃了,现在的Habana身上似乎也发生了同样的事情。英特尔目前正在使用他们的第二代Habana Gaudi 2,除了 AWS 上可用的一些实例外,几乎没有采用。此外,随着该产品被纳入 2025 Falcon Shores GPU,英特尔已经将路线图宣告失败。英特尔的 GPU,Ponte Vecchio 也好不到哪儿去。已经很晚了,直到最近才完成对拖延已久的 Aurora 超级计算机的交付,再过 2 年就没有继任者了。它的性能通常无法与 Nvidia 的 H100 GPU 竞争。
这就让AMD成为了英伟达的最后一个有力竞争者。
AMD 是唯一一家拥有成功交付用于高性能计算的芯片记录的公司。虽然这主要适用于他们的 CPU 端是一台运行良好的执行机器,但它还可以进一步扩展。AMD 于 2021 年为全球首台 ExaFLop 超级计算机 Frontier 交付了 HPC GPU 芯片。虽然为 Frontier 提供动力的 MI250X 足以完成其主要工作,但它未能在云计算和超大规模用户的大客户中获得任何影响力。
现在,每个人都期待着 AMD 的 MI300,它将于今年晚些时候交付给 El Capitan,这是他们的第二个 Exascale 超级计算机获胜者。出于这个原因,一旦您将目光脱离 Nvidia ,AMD 即将推出的 MI300 GPU 将成为讨论最多的芯片之一。我们也一直在密切关注其与Meta 的 PyTorch 2.0 和 OpenAI 的 Triton软件的适配前景。自 Nvidia 的 Volta GPU 和 AMD 的 Rome CPU 以来,数据中心芯片还没有引起如此大的轰动。

MI300,代号 Aqua Vanjaram,由多个复杂的硅层组成,坦率地说是工程奇迹。首席执行官 Lisa Su 今年早些时候在 CES 上展示了 MI300 套件,让我们了解 MI300 的结构。我们看到 4 个硅片被 8 个 HBM 堆栈包围。这是 HBM3 的最高 5.6 GT/s 速度,八个 16GB 堆栈形成 128GB 统一内存,带宽高达 5.734 TB/s。
与 3.3 TB/s 的 Nvidia H100 SXM 80GB 相比,其带宽增加了 72%,容量增加了 60%。
AMD 获得任何数量的 AI 计算美元的机会最终归结为成为 hyperscalers 与 Nvidia 的可靠第二来源。假设是涨潮会托起所有船只。当然,预计在 AI 数据中心基础设施上的大量支出将以某种方式使 AMD 受益。
AMD 硬件只是 AI 支出热潮中的一个注脚。事实上,目前 AMD 在生成 AI 基础设施建设方面相对失败,因为他们在数据中心 GPU 方面缺乏成功安利,在 HGX H100 系统中缺乏 CPU 胜利,以及 普遍放弃 CPU 支出。因此,MI300 的成功至关重要。
基本构建块 - Elk Range 有源中介层芯片
MI300 的所有变体都以称为 AID(active interposer die) 的相同基本构建块开始,即是所谓的有源中介层裸片。这是一款名为 Elk Range 的小芯片,尺寸约为 370mm²,采用台积电的 N6 工艺技术制造。该芯片包含 2 个 HBM 内存控制器、64MB 内存附加末级 (MALL) Infinity Cache、3 个最新一代视频解码引擎、36 通道 xGMI/PCIe/CXL,以及 AMD 的片上网络 (NOC)。在 4 块配置中,MALL 缓存为 256MB,而 H100 为 50MB。
AID 最重要的部分是它在 CPU 和 GPU 计算方面是模块化的。AMD 和台积电使用混合键合技术将 AID 连接到其他小芯片。这种通过铜 TSV 的连接允许 AMD 混合和匹配 CPU 与 GPU 的最佳比例。四个 AID 以超过 4.3 TB/s 的对分带宽相互通信,启用超短距离 (USR:Ultra Short Reach) 物理层,如 AMD Navi31 游戏 GPU 中的小芯片互连所示,尽管这次同时具有水平和垂直链路和具有对称的读/写带宽。方形拓扑还意味着对角线连接需要 2 跳(hops),而相邻 AID 需要 1 跳。
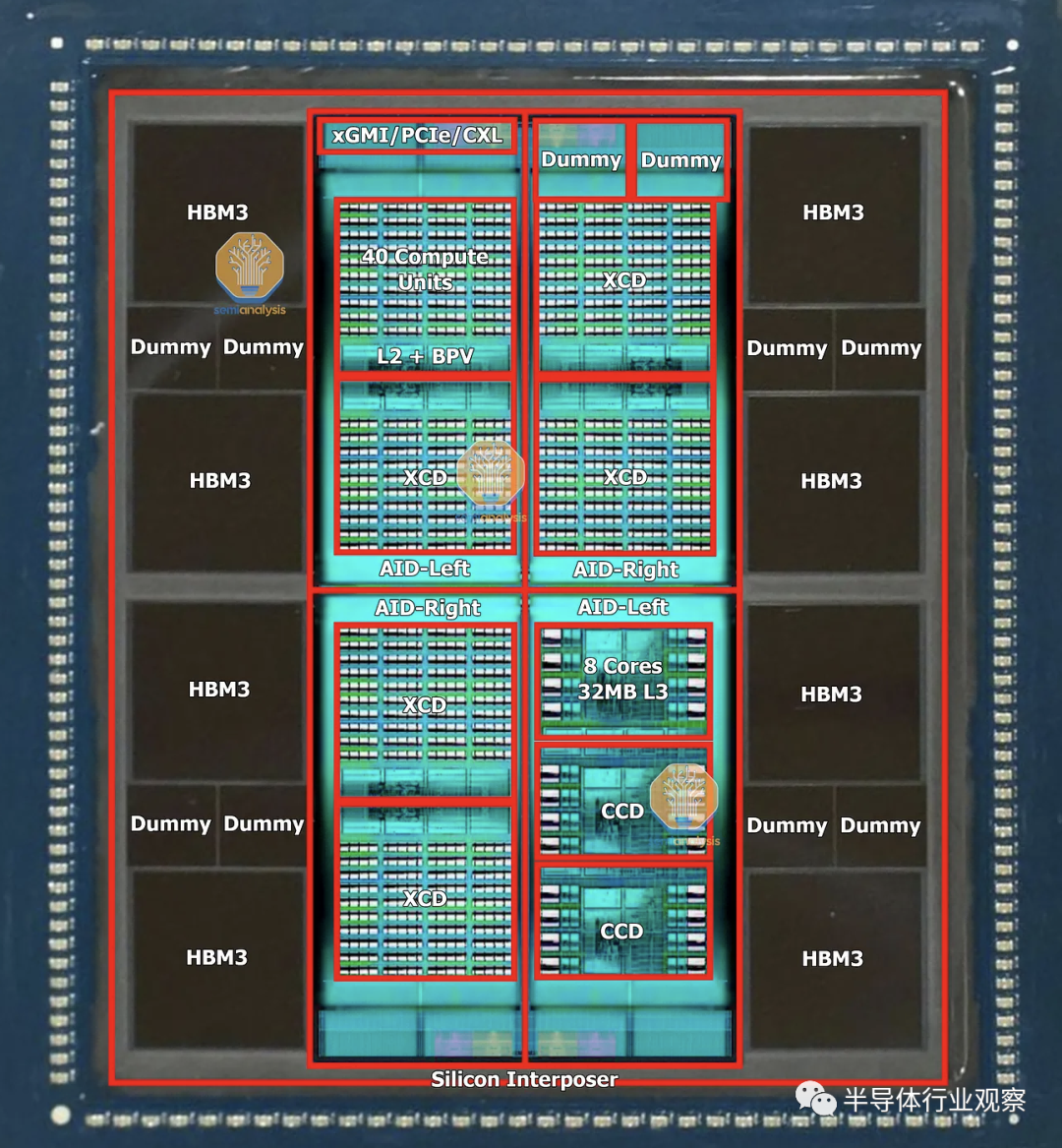
这些 AID 中的 2 个或 4 个(根据 MI300 变体具有不同的计算)在CoWoS 硅中介层的顶部组合在一起。AID 有两种不同的流片,它们的. T镜像很像英特尔的 Sapphire Rapids。
Compute Tiles——Banff XCD 和 DG300 Durango CCD
AID 之上的模块化计算块可以是 CPU 或 GPU。
在 GPU 方面,计算小芯片称为 XCD,代号为 Banff。Banff在 TSMC N5 工艺技术上制造,约为 ~115mm² 。尽管只启用了 38 个计算单元,但它总共包含 40 个计算单元。该架构由 AMD 的 MI250X 演变而来,在 GitHub 上,AMD 将其称为 gfx940,但公开称其为 CDNA3。它针对计算进行了优化,尽管是“GPU”,但不能真正处理图形。这同样适用于 Nvidia 的 H100,它们的大部分 GPC 都无法处理图形。
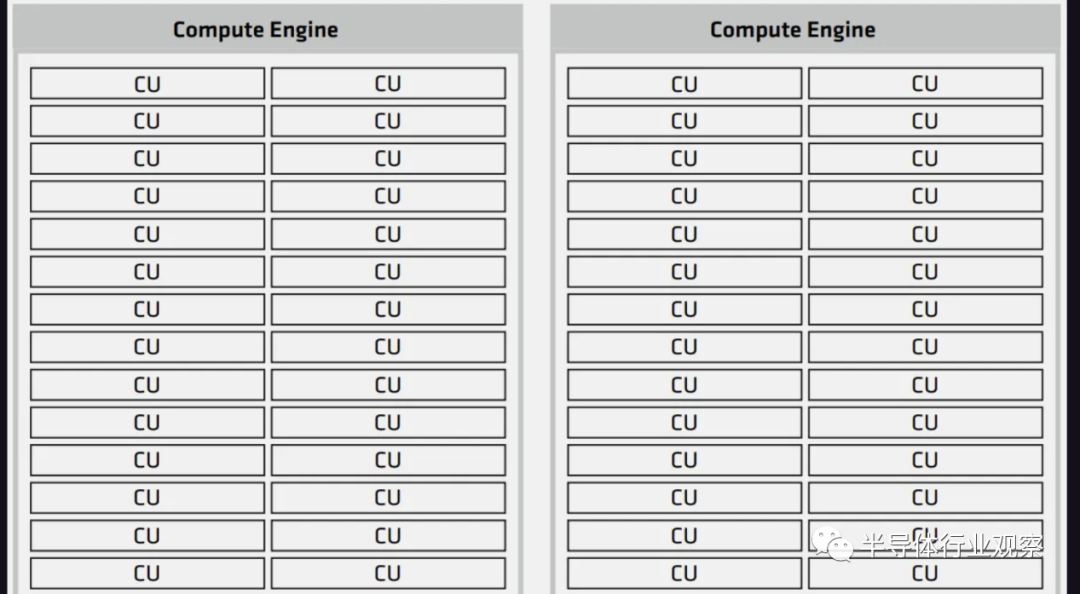
总的来说,每个 AID 可以有 2 个 Banff die,总共有 76 个 CU。MI300 的最大 XCD/GPU 配置将提供 304 个 CU。作为对比,AMD MI250X 具有 220 个 CU。
MI300 的另一个模块化计算方面是 CPU 方面。AMD 部分重用了他们的 Zen 4 CCD 小芯片,尽管进行了一些修改。他们改变了一些金属层掩模,为 SoIC 和 AID 创建焊盘,需要重新设计一些金属掩模的新流片。这个修改过的 Zen 4 CCD,GD300 Durango 禁用了 GMI3 PHY。AID 的带宽明显高于 GMI3。此 CCD 采用 TSMC 的 5nm 工艺技术,并保留与台式机和服务器上的 Zen 4 CCD相同的 ~70.4mm 2芯片尺寸。
每个 AID 可以有 3 个 Zen 4 小芯片,总共 24 个内核。MI300的最大CCD/CPU配置可以提供多达96个核心。
先进封装——品味未来
AMD 的MI300 是世界上最令人难以置信的先进封装形式。有超过 100 块硅粘在一起,全部位于使用 TSMC 的 CoWoS-S 技术的破纪录的 3.5x 光罩硅中介层之上。这种硅的范围从 HBM 存储层到有源中介层以进行计算,再到用于结构支持的空白硅。这个巨大的中介层几乎是 NVIDIA H100 上中介层的两倍。MI300 的封装工艺流程非常复杂,是行业的未来。

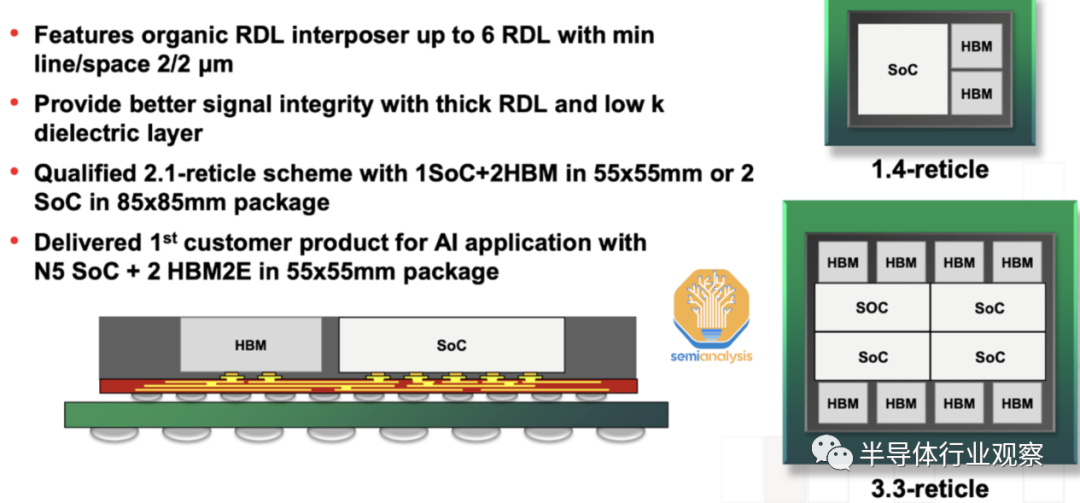
复杂的封装需要 AMD 的重大灵活性和修改才能按时获得 MI300。最初的设计是使用采用台积电CoWoS-R技术的有机再分布层 (RDL) 中介层。事实上,台积电去年确实推出了CoWoS-R测试封装,其结构与小米300有着惊人的相似之处。可能由于具有如此大尺寸的有机中介层的翘曲和热稳定性问题而改变了中介层材料。
AID 以 9um 间距与 SoIC gen 1 混合键合到 XCD 和 CCD。由于工艺不成熟,AMD 不得不放弃转向TSMC 的 SoIC gen 2 的计划,该 SoIC 的间距为 6um 。然后将它们封装在 CoW 无源中介层之上。通过这个过程有十几块支撑硅片。最终的 MI300 包含传统的倒装芯片质量回流和 TCB 以及晶圆上的芯片、晶圆上的晶圆和晶圆上的重构晶圆混合键合。
MI300 配置
AMD MI300 有 4 种不同的配置,但我们不确定是否所有 4 种都会真正发布。
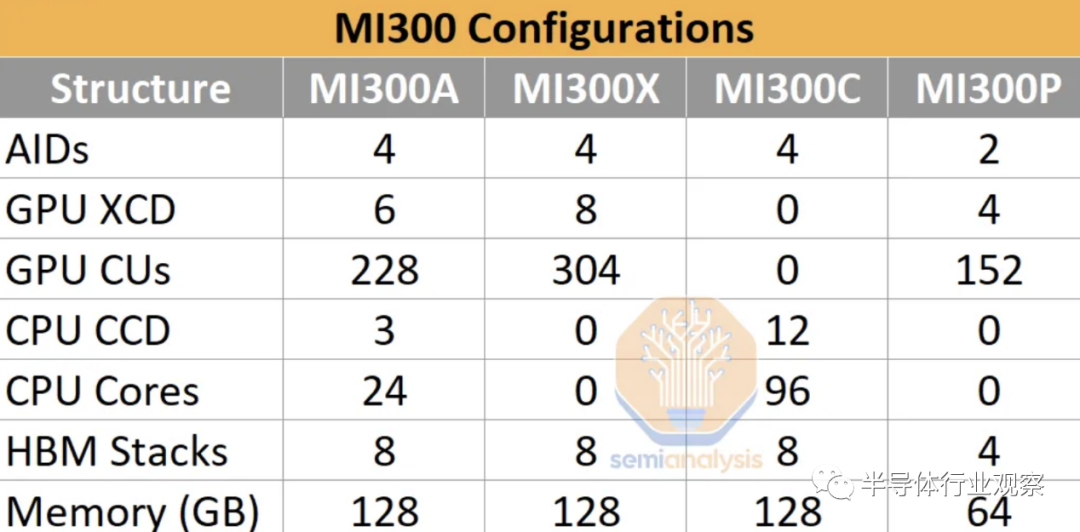
MI300A 凭借异构 CPU+GPU 计算成为头条新闻,El Capitan Exascale 超级计算机正在使用该版本。MI300A 在 72 x 75.4mm 基板上采用集成散热器封装,适合插槽 SH5 LGA 主板,每块板有 4 个处理器。它有效地支付了开发成本。它已经出货,但真正在第三季度出现增长。标准服务器/节点将是 4 个 MI300A。不需要主机 CPU,因为它是内置的。这是迄今为止市场上最好的 HPC 芯片,并将保持一段时间。
MI300X 是 AI hyperscaler 变体,如果成功,将成为真正的容量推动者。全是 GPU,以实现 AI 的最佳性能。AMD这里推的服务器级配置是8颗MI300X+2颗Genoa CPU。
MI300C 将走相反的方向,成为仅具有 96 核 Zen4 + HBM 的 CPU,以响应英特尔的 Sapphire Rapids HBM。然而,这个市场可能太小而且产品太贵,以至于 AMD 无法生产这个变体。
MI300P 就像一半大小的 MI300X。它是一种可以以较低功率进入 PCIe 卡的产品。这又需要主机 CPU。这将是最容易开始开发的版本,尽管我们认为它更像是 2024 年的版本。