来源:2022 IEEE Asian Solid-State Circuits Conference (A-SSCC)
作者:Heming Sun1,2,3, Qingyang Yi4, Fangzheng Lin1, Lu Yu2, Jiro Katto1, and Masahiro Fujita4
原文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9980666
整理人:何冰
内容摘要:本文提出了一种细粒度流水线结构,以实现较高的 DSP 效率。此外,还开发了级联 DSP 和跳零解卷功能,以提高硬件性能。
内容摘要
最近,学习图像压缩(LIC)在压缩比和重建图像质量方面都表现出了卓越的能力。通过采用变异自动编码器框架,LIC 可以超越最新传统编码标准 VVC 的内部预测。为了加快编码速度,大多数 LIC 框架都在 GPU 上使用浮点运算。然而,如果编码和解码在不同的平台上进行,浮点运算结果在不同硬件平台上的不匹配会导致解码错误。因此,非常需要采用定点运算的 LIC 。本文给出了 8 位定点量化 LIC 的 FPGA 设计。不同于现有的 FPGA 加速器,我们提出了一种细粒度流水线结构,以实现较高的 DSP 效率。此外,还开发了级联 DSP 和跳零解卷功能,以提高硬件性能。
编解码器结构
图 1 描述了编码和解码的神经网络结构。我们采用了 [1] 中的超前置结构。编码由分析变换(AT)、超分析变换(HA)和超合成变换(HS)组成。AT 将原始图像 x 转换为潜码 y,HA 将潜码 y 转换为潜码 z,并将其传输到主机 PC 进行范围编码。HS 生成 y 的均值 μ 和尺度 σ,并将它们发送到主机 PC。解码由合成变换 (ST) 和 HS 组成。首先,使用一个范围解码器根据比特流恢复 z,然后将 z 输入 HS 以生成 y 的 μ 和 σ。最后,将 y 输入 ST,生成重建图像 x'。
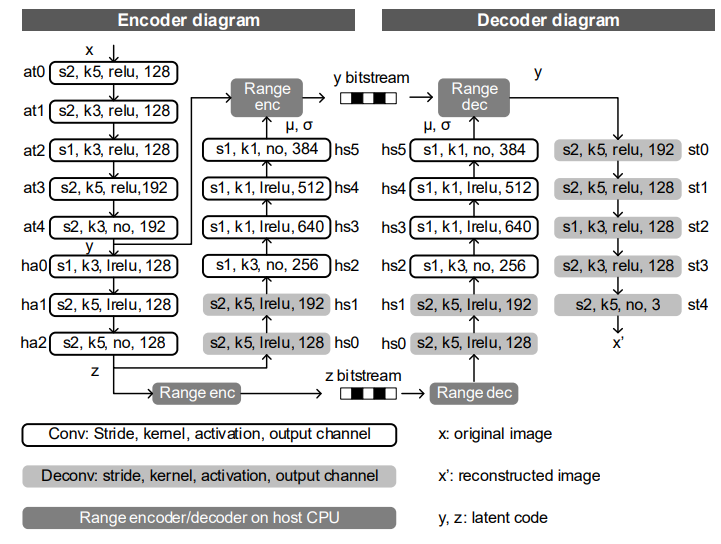
图 1:编解码器网络结构
整体架构
图 2 显示了整体架构和流水线示例。所有参数一次性存储在外部存储器中,输入图像在执行过程中传输到 DDR。输入缓冲区存储第一层的需求行,输出缓冲区存储最后一层的计算结果。为了支持流水线,每一层都有自己的处理元件,主要由乘法累加单元 DSP 组成。我们从内核宽度(k)、输入通道(c)和输出通道(m)三个维度利用并行性。在遍历所有输入通道、输出通道和内核高度后,就可以生成一个输出元素。因此,生成一行所需的周期是 c、m 和 k 的函数。在两个连续层之间设计了一个自适应激活(act)缓冲区,以支持细粒度的 DSP 分配。行为缓冲区由多个行缓冲区组成,利用乒乓机制轮流写入和读取每个行缓冲区。为了支持灵活选择通道并行性,我们在行缓冲器的输入和输出侧使用了横杆。多个 BRAM(RAMB18K)片用于存储所有通道的结果。每个 BRAM 可配置为 8b×2048、16b×1024 或 32b×512。为了提高 BRAM 的深度效率,我们从最浅的 32b×512 开始配置 BRAM。如果在写入或读取时出现地址冲突,我们会将宽度减半,深度加倍。
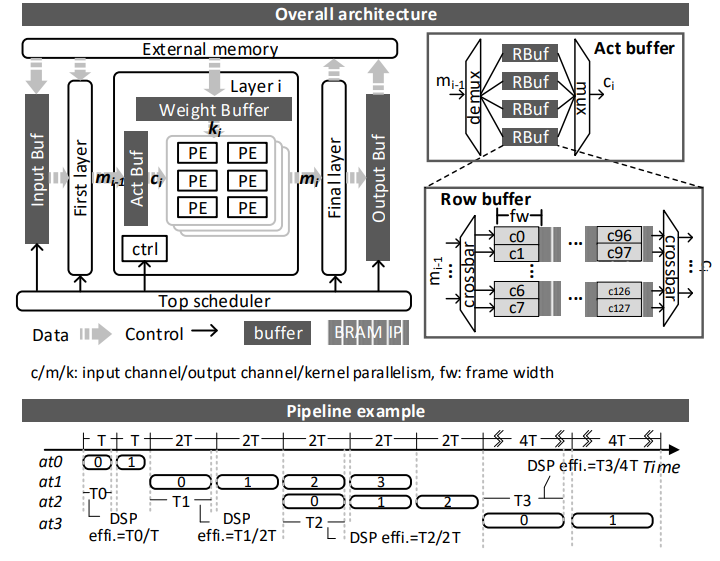
图 2:整体架构以及流水示意
PE设计以及级联DSP
图 3 描述了处理元件的结构, c 个输入通道和 m 个输出通道并行处理。对于特定的输入通道和输出通道,并行计算内核宽度的 MAC 运算。按照权重固定机制,每个输入激活(iact)与宽度方向上的所有内核相乘。两个输出通道的两个权重共享一个 DSP,与同一个 iact 相乘。此外,我们还提出了级联 DSP(casDSP),用于在 DSP 内部计算核宽偏和(psum)。DSP 的指令配置为 (A+D)xB+C。两个权重分别分配在 A 端口的 LSB 和 D 端口的 MSB,以尽可能避免遮挡。B 端口用于 iact,C 端口用于传输两个 psum 结果。当使用支持 25x18b 的 DSP48E1 时,较低 psum 的余量仅为 17b。如果内核宽度大于 2,就会出现溢出问题。为了避免溢出,在将低位和数值级联到下一个级联之前,先分割 MSB,使有效位数在 16b 以内。使用额外的链将分割后的 MSB 相加。最后,将相加的 MSB 与较低的 psum 合并。对于较高的 psum,由于 C 端口的位宽可以达到 48b,因此无需拆分 MSB。

图 3:PE设计以及级联DSP
反卷积操作示意
图 4 展示了步长为 2、内核为 5x5 的解卷积操作。输入值为 3x3,在跨距为 2 的情况下,首先通过插入零元素将输入值扩大为双倍大小。然后,将扩张后的输入与内核卷积,得出结果。我们提出了两种跳过插入零输入计算的方法。1) 从列的角度看,每个卷积都包含三个或两个非零输入列,并交替包含跨步窗口,因此我们分别提供了一个带有三个 DSP 的 casDSP 和一个带有两个 DSP 的 casDSP。通过向两个 casDSP 广播每个 iact,可以同时生成相邻两列的结果。2) 在我们的数据流中,内核是逐行遍历的。在遍历过程中,内核的每一特定行将只用于相邻行的两次卷积中的一次。在两次卷积之间,首先产生两个非零输入行的卷积结果,然后产生需要三个非零输入行的结果。

图 4:带零跳变的解卷积
DSP效率评估以及实验结果分析
图 5 评估了 DSP 效率。由于输入和输出通道并行性的灵活性,与之前限制通道并行性为 2 次幂的流水线工作[2]相比,我们可以实现更高的 DSP 效率。在 VCU118 上进行 720p@41fps 编码和 720p@36fps 解码时,几乎所有层的 DSP 效率都超过了 90%。对于其他评估板,可根据板的资源规模实现不同的编码速度。不过,在所有编码和解码情况下,DSP 效率平均都大于 90%。

图 5:DSP效率评估
图 6 显示了与其他 LIC 实现方法的比较。与 [3] 相比,我们的方法以更低的每像素比特(bpp)获得了更好的 PSNR。此外,我们的编码帧速(fps)提高了 1.31 倍至 1.49 倍,解码帧速提高了 4.95 倍至 5.61 倍。解码速度大大加快得益于在解卷积中建议的跳零和相对较轻的 LIC 模型。我们的设计每帧功耗也低于 [3]。我们还与嵌入式 GPU(Jetson Xavier NX)和强大的 GPU(RTX 3090)进行了比较。虽然浮点精度能获得更好的编码增益,但它阻碍了跨平台编码的可能性。与 Jetson 相比,帧频可提高 4.43-5.81 倍。在 FPGA 芯片采用前者工艺技术的情况下,我们仍能达到与 Jetson 相当的能效。与 RTX 3090 相比,我们的速度提高了 2.15 倍。由于 GPU 利用率低,因此能效也更高。我们还提供了资源利用率。所有情况下的工作频率都是 200MHz。

图 6:实验结果
引用
[1] H. Sun et al., "Learned Image Compression with Fixed-point Arithmetic", IEEE PCS, pp. 1-5, June 2021.
[2] X. Zhang et al., "DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs", IEEE/ACM ICCAD, pp. 1-8, Nov. 2018.
[3] C. Jia et al., "FPX-NIC: An FPGA-Accelerated 4K Ultra-high-definition Neural Video Coding System", IEEE Trans. CSVT, 2022.
本文转载自: 媒矿工厂微信公众号