在今天于旧金山举行的推进人工智能(Advancing AI)大会上,AMD发布了新一代MI325X人工智能加速器,将其Instinct加速器的VRAM提升至256 GB HBM3e。

该部件以 AMD 之前发布的去年底推出的 MI300 加速器为基础,但将 192 GB HBM3 模块换成了 256 GB 速度更快、容量更大的 HBM3e。这种方法在很多方面与 Nvidia 去年推出的 H200 更新版类似,后者保持了原有的计算功能,但增加了内存容量和带宽。
对于许多人工智能工作负载来说,内存容量越大、速度越快,性能就越高。AMD 试图通过在芯片中加入更多 HBM 来区别于 Nvidia,这使得 AMD 成为像微软这样希望在更少的节点上部署万亿次参数规模模型(如 OpenAI 的 GPT4o)的云提供商的一个有吸引力的选择。

AMD 最新 Instinct GPU 拥有 256 GB HBM3e、6 TB/s 内存带宽和 1.3 petaFLOPS 的密集 FP16 性能
在今年春季的 Computex 上,AMD 首次预告这款芯片将搭载 288 GB 的 VRAM,比上一代产品多出 50%,是其主要竞争对手 Nvidia 141 GB H200 的两倍。
四个月后,AMD 显然改变了主意,转而坚持使用 8 个 32 GB 的 HBM3e 堆栈。AMD GPU 平台副总裁布拉德-麦克雷迪(Brad McCredie)周四在旧金山举行的 “加速人工智能”(Accelerating AI)活动现场对我们说,改变的原因在于产品开发初期的架构设计。
“他说:"实际上,我们在 Computex 上曾说过,最高可达 288 GB,这就是我们当时的想法。“很久以前,我们在 GPU 方面的芯片设计上就做出了一些架构决定,我们要在软件上做一些我们认为性价比不高的事情,而我们已经去实现了 256 GB。”“AMD 数据中心 GPU 部门副总裁 Andrew Dieckmann 重申:"这就是我们该产品的优化设计点。
虽然该加速器的内存密度可能没有他们最初希望的那么高,但它的内存带宽仍然达到了 6 TB/s,比老款 MI300X 的 5.3 TB/s高出不少。在更高的容量和内存带宽(每个节点 2 TB 和 48 TB/s)之间,这应该有助于加速器支持更大的机型,同时保持可接受的生成率。
奇怪的是,所有这些额外内存的功耗都有相当大的增加,从 250 瓦增加到 1,000 瓦。这使它在 TDP 方面与 Nvidia 即将推出的 B200 处于同一水平。遗憾的是,虽然功耗增加了,但该芯片的浮点精度似乎并没有从上一代产品的 1.3 petaFLOPS(密集 FP16)或 2.6 petaFLOPS(FP8)提高多少。
不过,AMD 坚称,在实际测试中,该芯片在 Llama 3.1 70B 和 405B 的推理性能上分别领先 Nvidia 的 H200 20%-40%。在训练 Llama 2 70B 时,性能更为接近,AMD 声称单个 MI325X 的优势约为 10%,系统级性能相当。
AMD Instinct MI325X加速器目前正按计划于第四季度生产出货,戴尔科技、Eviden、技嘉科技、惠普企业、联想、超微等公司的系统将于2025年第一季度投放市场。
2025 年下半年将实现更高性能
虽然 MI325X 可能不会配备 288 GB HBM3e,但 AMD 的下一款 Instinct 芯片 MI355X 将于明年下半年上市。
该芯片基于 AMD 即将推出的 CDNA 4 架构,还承诺提供更高的浮点性能,在使用该架构支持的新 FP4 或 FP6 数据类型时,最高可达 9.2 密 petaFLOPS。如果 AMD 能够实现这一目标,那么它将与 Nvidia 的 B200 加速器直接竞争,后者的密集 FP4 性能约为 9 petaFLOPS。
对于那些仍在使用 FP/BF16 和 FP8 数据类型运行更传统的人工智能工作负载(有趣的是,现在已经有这种东西了)的用户,AMD 表示其性能提升了约 80%,分别达到 2.3 petaFLOPS 和 4.6 petaFLOPS。
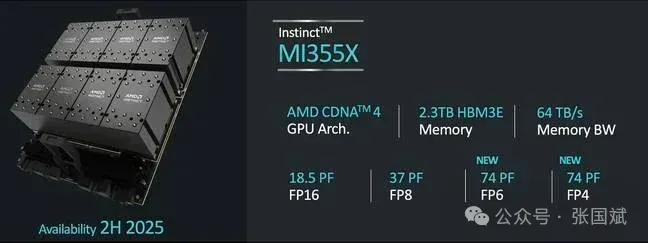
据报道,AMD 的下一代 MI355X 将实现其 288 GB 的承诺,并将系统性能提升至 FP4 的 74 petaFLOPS。据 AMD 称,在 8 个 GPU 节点中,这将扩展到 2.3 TB 的 HBM 和 74 petaFLOPS 的 FP4 性能--足以将 42 亿个参数模型装入这一精度的单个盒子中。
在推出新加速器的同时,AMD 还预告将于明年初推出其对 Nvidia InfiniBand 和 Spectrum-X 计算结构以及 BlueField 数据处理器的回应。由 AMD Pensando 网络团队开发的 Pensando Pollara 400 预计将成为首款支持超以太网联盟规范的网卡。
在人工智能集群中,这些网卡将支持用于在多个节点上分配工作负载的扩展计算网络。在这些环境中,丢包会导致较高的尾部延迟,从而缩短训练模型的时间。根据 AMD 的数据,平均有 30% 的训练时间用于等待网络跟上。
Pollara 400 将配备一个 400 GbE 接口,同时支持与我们从 Nvidia、Broadcom 和其他公司那里看到的相同类型的数据包喷射和拥塞控制技术,以实现类似 InfiniBand 的数据包丢失和延迟。
Pensando 团队热衷于强调的一个不同点是使用了可编程 P4 引擎,而不是固定功能的 ASIC 或 FPGA。由于超以太网规范仍处于起步阶段,预计会随着时间的推移而不断发展。因此,一个可以快速重新编程以支持最新标准的部件为早期采用者提供了一定的灵活性。
与 Nvidia 的 Spectrum-X 以太网网络平台相比,Pollara 的另一个优势是 Pensando 网卡,它不需要兼容交换机就能实现超低损耗网络。除了后端网络外,AMD 还推出了名为 Salina 的 DPU,它具有两个 400 GbE 接口,旨在通过从 CPU 卸载各种软件定义网络、安全、存储和管理功能,为前端网络提供服务。这两款产品均已向客户提供样品,预计将于 2025 年上半年全面上市。