来源:内容编译自theregister,谢谢。
2017 年,AMD 推出代号为 Naples 的第一代 Epyc 处理器后不久,英特尔就打趣说,其竞争对手为了保持相关性,已经沦落到只能将一堆台式机芯片粘在一起的地步。
不幸的是,对于英特尔来说,这句评论已经过时了,短短几年后,这家 x86 巨头就开始自己寻找粘合剂了。
英特尔的Xeon 6处理器于今年开始分阶段推出,这是其第三代多芯片 Xeon 处理器,也是其首款采用与AMD自己的异构芯片架构类似的数据中心芯片。
虽然英特尔最终认识到了AMD小芯片战略的明智之处,但其方法却截然不同。
突破标线限制
快速回顾一下为什么这么多 CPU 设计正在远离单片架构,这主要归结为两个因素:掩模版限制和产量。
一般而言,在工艺技术没有重大改进的情况下,更多内核必然意味着更多硅片。然而,芯片实际尺寸存在实际限制 - 我们称之为光罩极限 - 大约为 800 平方毫米。一旦达到极限,继续扩展计算的唯一方法就是使用更多芯片。
我们现在看到许多产品(不仅仅是 CPU)都采用了这种技术,它们将两个大型芯片塞进一个封装中。Gaudi 3、Nvidia的Blackwell和英特尔的Emerald Rapids Xeons 只是其中几个例子。
多芯片的问题在于,它们之间的桥梁往往是带宽方面的瓶颈,并且有可能引入额外的延迟。这通常不像将工作负载分散到多个插槽那么糟糕,但这也是一些芯片设计师倾向于使用较少数量的较大芯片来扩展计算的原因之一。
然而,制造更大的芯片确实成本高昂,因为芯片越大,缺陷率就越高。这使得使用大量较小的芯片成为一个有吸引力的提议,并解释了为什么AMD的设计使用了如此多的芯片——最新的Epycs芯片多达 17 个。
了解了这些基础知识后,让我们深入探讨一下英特尔和AMD最新Xeons和Epyc处理器的不同设计理念。
AMD的做法
我们将从AMD的第五代Epyc Turin处理器开始。具体来说,我们正在研究该芯片的 128 核 Zen 5 版本,它具有 16 个4nm核心复合芯片 (CCD),这些芯片围绕着基于台积电 6nm 工艺技术制造的单个 I/O 芯片 (IOD)。

AMD 最新的Epycs配备多达 16 个计算芯片
如果这听起来很熟悉,那是因为 AMD 在其第二代 Epyc 处理器上使用了相同的基本公式。作为参考,第一代Epyc缺乏独特的 I/O 芯片。
正如我们前面提到的,使用大量较小的计算芯片意味着 AMD 可以获得更高的产量,但这也意味着他们可以在 Ryzen 和 Epyc 处理器之间共享硅片。

如果这些芯片看起来很熟悉,那是因为 AMD 的 Epyc 和 Ryzen 处理器实际上共享相同的计算芯片。
此外,使用八核或十六核 CCD(每个 CCD 具有 32 MB 的 L3 缓存),AMD 在按缓存和内存比例扩展核心数量时可以获得额外的灵活性。
例如,如果您想要一个具有 16 个内核的 Epyc(由于许可限制,这是 HPC 工作负载的常见 SKU),最明显的实现方法是使用两个八核 CCD,两个 CCD 之间有 64 MB 的 L3 缓存。但是,您也可以使用 16 个 CCD,每个 CCD 只有一个内核处于活动状态,但板载缓存为 512 MB。这听起来可能很疯狂,但这两种芯片确实存在。
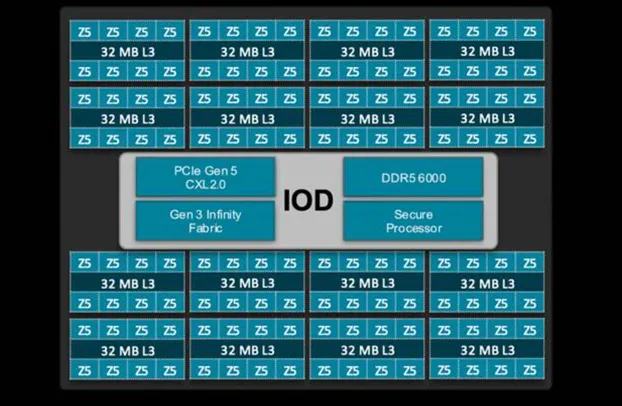
AMD 的第五代Epycs遵循熟悉的模式,即16个计算芯片围绕一个中央 I/O 芯片。
另一方面,I/O 芯片负责除计算之外的几乎所有功能,包括内存、安全性、PCIe、CXL 和其他 I/O(如 SATA),并且还充当芯片 CCD 与其他插槽之间通信的骨干。
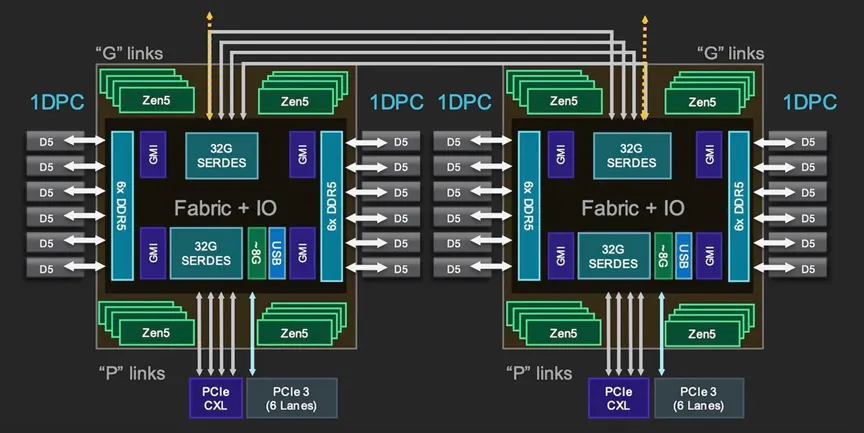
以下是对 AMD Epyc Turin I/O 芯片的详细介绍。
将内存控制器放置在I/O芯片上确实有一些优点和缺点。从好的方面来说,这意味着内存带宽在很大程度上独立于核心数量而扩展。缺点是某些工作负载的内存和缓存访问延迟可能会更高。我们强调“可能”,因为这种事情高度依赖于工作负载。
英特尔Xeon的chiplet 之旅
谈到英特尔,这家芯片制造商对多芯片硅片的处理方式与 AMD 有很大不同。虽然现代 Xeon 处理器采用具有不同计算和 I/O 芯片的异构架构,但情况并非总是如此。
英特尔首款多芯片 Xeon 处理器,代号为Sapphire Rapids,采用一块单片、中等核心数芯片或四块极端核心数芯片,每块芯片都有自己的内存控制器和板载 I/O。Emerald Rapids采用了类似的模式,但为芯片核心数较高的 SKU 选择了两块更大的芯片。

正如您在 Sapphire 和 Emerald Rapids 之间看到的,英特尔从四个中型芯片转换为一对近乎网状的有限芯片。
所有这一切都随着 Xeon 6 的推出而发生了改变,英特尔将I /O、UPI 链接和加速器移至基于英特尔 7 工艺节点制造的一对芯片上,这对芯片位于基于英特尔 3 制造的中心的一到三个计算芯片之间。
出于稍后会讲到的原因,我们将主要关注英特尔更主流的 Granite Rapids Xeon 6 处理器,而不是其多核 Sierra Forest 部件。
看看英特尔的计算芯片,我们就能发现它与 AMD 的第一个重大区别。每个计算模块至少有 43 个板载核心,可根据 SKU 开启或关闭融合。这意味着英特尔实现 128 个核心所需的芯片数量比 AMD 少得多,但由于面积较大,因此成品率可能会更低。

根据 SKU,Granite Rapids 使用夹在一对 I/O 芯片之间的一到三个计算芯片。
除了增加内核之外,英特尔还选择将这些芯片的内存控制器放在计算芯片上,每个芯片支持 4 个通道。理论上,这应该可以降低访问延迟,但这也意味着,如果你想要所有 12 个内存通道,就需要填充所有 3 个芯片。
对于我们上个月看过的 6900P 系列部件,你不必担心这一点,因为每个 SKU 都配有三个计算芯片。然而,这意味着 72 核版本只利用了封装中一小部分硅片。同样,我们之前讨论过的 16 核 HPC 中心 Epyc 也是如此。
另一方面,英特尔将于明年初推出的 6700P 系列部件将配备一个或两个计算芯片,具体取决于所需的内存带宽和核心数量,这意味着内存通道在高端将限制为 8 个,在板载单个计算芯片的配置中可能只有 4 个。我们目前还不清楚 HCC 和 LCC 芯片上的内存配置,因此英特尔有可能增强了这些部件上的内存控制器。
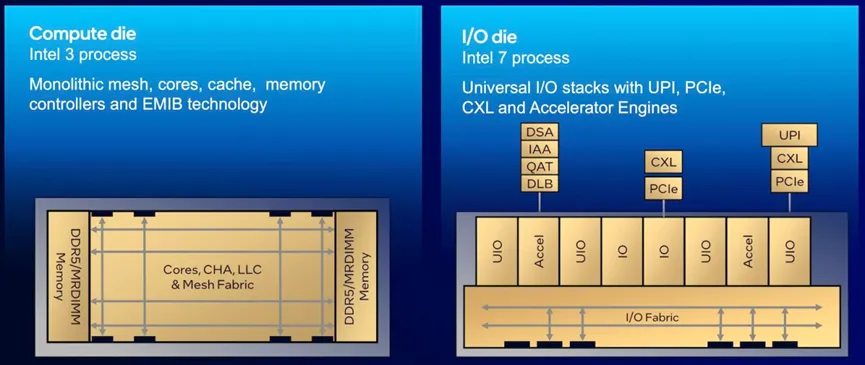
与 AMD 的 Epyc 一样,英特尔的 Xeon 现在采用带有计算和 I/O 芯片的异构芯片架构。
英特尔的 I/O 芯片也相当薄,并包含 PCIe、CXL 和 UPI 链路组合,用于与存储、外围设备和其他插槽进行通信。除此之外,我们还发现了许多用于直接流 (DSA)、内存分析 (IAA)、加密/解密 (QAT) 和负载平衡的加速器。
我们得知,在 I/O 芯片上放置加速器的部分原因是为了让它们更靠近进出芯片的数据。
我们接下来要去哪里?
从表面上看,英特尔的下一代多核处理器代号为 Clearwater Forest,预计将于明年上半年推出,其型号与 Granite Rapids 类似,具有两个 I/O 模块和三个计算模块。

它可能看起来像缩小版的 Granite Rapids,但显然那只是隐藏着更多芯片的结构硅。
然而,外表是会骗人的。据我们了解,这三个计算芯片实际上只是隐藏着许多较小计算芯片的结构硅片,而这些较小的计算芯片本身位于有源硅片中介层之上。
根据英特尔今年早些时候展示的效果图,Clearwater Forest 每个封装最多可使用 12 个计算芯片。使用硅中介层绝不是新鲜事,它提供了许多好处,包括芯片间带宽更高、延迟比有机基板中通常看到的更低。这与英特尔核心数最高的 Sierra Forest 部件上的一对 144 核计算芯片大不相同。

如果英特尔今年早些时候发布的渲染图有任何可参考之处,那么 Clearwater Forest 隐藏的芯片数量要比 Granite Rapids 多得多
当然,讨论 Clearwater 森林将使用的技术的效果图并不意味着明年到达时我们将会得到完全相同的技术。
也许更大的问题是 AMD 下一步将把其小芯片架构带向何方。看看 AMD 的 128 核 Turin 处理器,封装上没有太多空间容纳更多硅片,但 House of Zen 仍有一些选择。
首先,AMD 可以选择更大的封装,为额外的芯片腾出空间。或者,该芯片制造商也可以将更多内核封装到更小的芯片上。然而,我们怀疑 AMD 的第六代 Epycs 最终可能看起来更像其 Instinct MI300 系列加速器。

MI300A 将 24 个 Zen 4 核心、6 个 CDNA 3 GPU 芯片和 128GB HBM3 内存整合到一个封装中,旨在满足 HPC 工作负载的需求
您可能还记得,与 MI300X GPU 一起推出的还有一款 APU,它将芯片的两个 CDNA3 模块换成了三个 CCD,中间有 24 个 Zen 4 核心。这些计算模块堆叠在四个 I/O 芯片上,并连接到一组八个 HBM3 模块。
现在,这只是猜测,但不难想象 AMD 会做类似的事情,将所有内存和 GPU 芯片换成额外的 CCD。这样的设计可能也会受益于更高的带宽和更低的芯片间通信延迟。
这是否真的会实现,只有时间才能证明。我们预计AMD的第6 代Epycs 将于 2026 年底上市。
原文链接:https://www.theregister.com/2024/10/24/intel_amd_packaging/
本文转载自:半导体行业观察