编者注:这是一篇来自一位工业、视觉、医疗和科学市场领域的人工智能系统架构师Quenton Hall的文章。
您可能不太熟悉百度的 DeepSpeech2 自动语音识别(ASR, Automatic Speech Recognition)模型,但我敢打赌,当您正在阅读本文的时候,语音识别其实已经成为您日常生活的一部分,比如 Siri,小爱同学,小度......
ASR 技术的起源可以追溯到20世纪40年代末和50年代初。1952年,贝尔实验室(Davis,Biddulph,Balashek)设计了“AUDREY”,这是一种“自动数字识别”设备,可以识别 0-9 位数字。该系统可以针对每个用户进行训练(实际是经过调制(tuned)的),对通过扬声器说话人的语音识别准确率可以达到90%以上,对说话人之外的语音识别准确率可以达到50-60%。
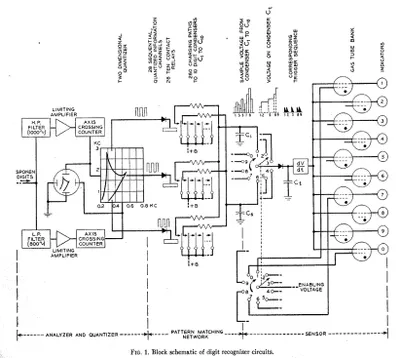
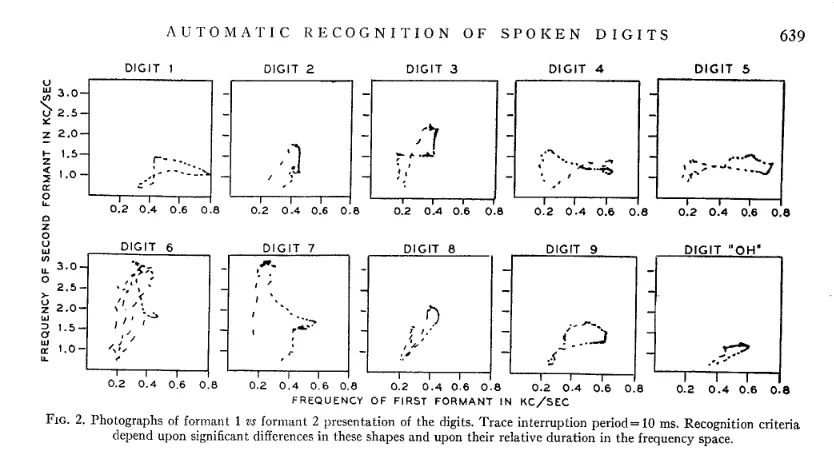

在接下来的60年里,业界针对ASR应用开发了许多不同的技术,经常采用的是原子级的、音素级的手工特征提取,后来发展到使用基于音素训练的深层神经网络以及后来的单词识别。这些系统通常是专有的,难以训练的,且缺乏准确性和词汇量。它们基本上仍是“玩具”。
2015年,被称为为“中国Goolge”的百度,发布了DeepSpeech2。百度首席科学家Andrew Ng领导了这个崭新的端到端ASR模型的开发,他表示“在未来,我希望能够和所有的设备进行对话,并让他们了解我们的需求。我希望有一天,我的子孙们会对我们当前的现状感到不可思议,比如他们会不理解当您对微波炉说“嗨”的时候,微波炉竟然只会粗鲁地坐在那里,而不搭理您”。虽然我最近没有和微波炉说过话,但很明显迟早我都会与微波炉对话的的(我妻子会告诉你我已经做过这件事了,但正如保罗·萨瑟兰在那场哈米仓鼠秀上所说的“……那是另一个故事……”)。
端到端ASR系统的优势在于,它们既不用手工特征提取的特性,也不针对音素或单词训练,而是针对大数据语音语料库中语音数据的标注而进行训练。DeepSpeech2 利用了卷积、完全连接和双向LSTM层的组合,并接受了普通话和英语的识别训练。该模型使用包含口音和背景噪声的数据集进行训练。最终的结果是一个可以超过人工转录速度的模型。但是带口音的语音和噪声语音样本的转录,则比人工有着更高的 WERs(单词错误率),但估计这主要是由于相关训练数据的大小(口音)和综合(噪声)性质而造成的。
在嵌入式应用程序中使用赛灵思成本优化型MPSoC器件的赛灵思客户,很快将有机会在其平台中利用DeepSpeech2。赛灵思设计团队在印度已经实现了一个完整的C/C++模式,在LIVELIST数据集上进行训练,支持英语ASR。
由于模型是用C编写的,因此不需要运行时解释或推理框架,从而可以获得最佳性能。

赛灵思的实现方案是一个密集的模型(没有删减),它在既没有量化,也未利用2层CNN和5层双向LSTM(627800)的情况下部署。该模型的 WER仅为10.357,并且仅仅只用到250MB的PS-DDR内存。
如果您对ASR的边缘应用感兴趣,可以给小编留言,或联系您当地的赛灵思FAE或销售团队,我们将尽可能与您联系,并进行现场演示!
文章来源:Xilinx赛灵思官微