作者:曾书霖

AI 观察室是 Xilinx 在 2020 年打造的全新 AI 专栏,旨在分享产业洞见、解读前沿技术与热门应用。欢迎所有致力于 AI 研究与应用的有识之士投稿,邮件请发至:china_pr@xilinx.com
本期导读
云计算已经成为了一种新的计算范式。对于云计算而言,虚拟化是一项必不可少的技术,通过将硬件资源虚拟化,可以实现用户之间的隔离、系统的灵活可扩展,提升安全性,使得硬件资源可被充分利用。
从 2017 年起,因为FPGA的高可编程性、低延迟、高能效等特点,越来越多的云服务提供商,如 Amazon、阿里云、微软 Azure,都开始在云端提供了赛灵思 FPGA 实例,迈出了云计算发展的重要一步。然而截至目前,FPGA 云服务仍以物理卡的形式、面向单一的静态任务,没有很好的针对云端 FPGA 虚拟化的解决方案。最近,在 FPGA 领域顶级学术会议 FCCM2020 上,清华大学汪玉教授研究小组就这一课题实现了重要突破。—— 姚颂,赛灵思人工智能业务高级总监
开创先河
探索 FPGA 虚拟化之路
曾书霖:一直以来,我们团队的研究重点都是以移动端神经网络加速器为基础,在此之上思索如何推广到云端数据中心进行扩展。为了适配云端的虚拟化特性,从硬件架构到软件设计都要实现对虚拟化的支持。2019 年我们发现,虽然在 CPU 和 GPU 上针对AI应用已经有很多支持虚拟化的解决方案,但是在 FPGA 领域还缺乏相对成熟的方案。于是,我们决定在 FPGA 上面同时针对深度学习和虚拟化进行研究,力图实现 AI 应用在云端数据中心的高效部署。简单来讲,就是研究如何让多个用户的 AI 应用能够同时在一个 FPGA 上高效、可靠、灵活地运行起来。
举个例子,数据中心工作负载有一个重要特性,就是不仅存在多个用户,而且工作负载是的。针对数据中心多任务和动态负载的特点,深度学习加速器既要能够支持这种多任务并发执行,同时也需要适应快速的动态负载变化。基于这种思考,我们的研究定位于对原有移动端只能支持单任务和静态负载的神经网络加速器进行拓展,使之可以支持多任务并发和动态负载支持的虚拟化加速器设计。
为此,我们通过多核硬件资源池、基于分块 (tilling) 的指令封装、两级静态与动态编译的方式,实现了任务间的分离,同时还能保证快速在线重编程。
在今年5月举行的 FPGA 领域顶级会议 FCCM 2020 上,我们团队发表了针对深度学习加速的 FPGA 虚拟化方案。通常在 FCCM 这样的顶级学术会议,只有评分最高的论文才会被接收,并且接收率只有 20%。因此,论文能被接收对我们团队研究工作是极大的认可与鼓励。这篇论文已经发布在 Arxiv 平台,有兴趣的朋友可以前往下载。
https://arxiv.org/abs/2003.12101
痛点驱动
硬件重配置带来的时间及开销压力
曾书霖:在研究中,我们对公有云和私有云两种场景进行了区分(如下图所示)。公有云主要强调用户之间的隔离,包括资源隔离和性能隔离。
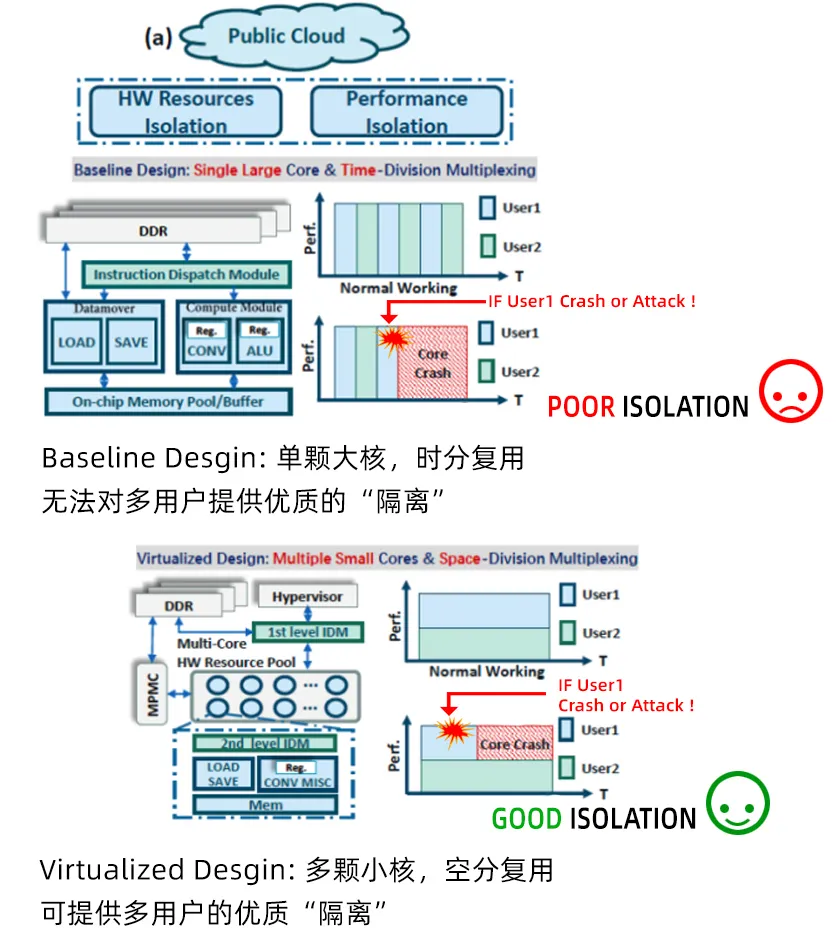
私有云(如下图)更像单独为一个企业或用户搭建的服务器,这个服务器要能够支持多个用户或多个任务同时执行,换句话说,就是对硬件资源持续且最大化的性能和资源利用。这种情况下,就要根据不同任务负载情况实现资源的动态划分。因此,随着负载变化愈加频繁,每次负载变化都会导致整个硬件资源的重配置。我们在研究中针对不同场景进行分析,也是为了找到一种途径从而有效降低整体重配置时间。
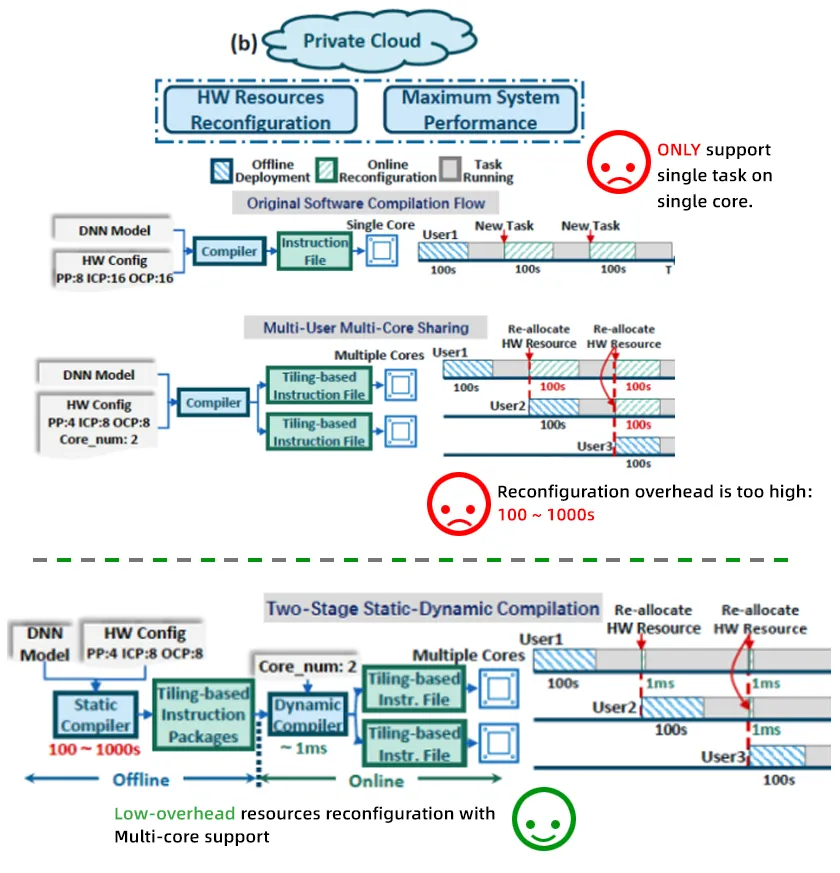
另一方面,一类神经网络加速器主要是基于HLS开发,它的特点是每一次神经网络模型发生变化时,硬件加速器也会发生相应变化,这就意味着每当用户的任务或负载发生变化,它都需要重新生成一个加速器,即重新利用 Vivado® 生成一个新的硬件比特流,这方面的时间开销是无法接受的。
与之相比,以赛灵思 DPU 加速器为代表的基于指令集的深度学习加速器,则可以通过指令集方式支持不同神经网络模型。也就是说,当用户任务或者负载发生变化时,无需重新生成硬件比特信息,而只需要利用软件编译器去生成对应指令,但这个过程依然比较慢,且频繁的重配置甚至可能会严重影响用户的任务进度。从这一维度来讲,我们也希望把重配置时间尽可能降低。
Alveo+阿里云
FPGA 虚拟化研究的实验环境
曾书霖:这一研究的最初想法诞生于 2019 年 5 月。在一年的时间里,我们从产生想法到搭建论文框架,再到不断完善,通过团队通力合作逐渐充实论文内容。刚开始我们只考虑了云端场景,针对虚拟化和加速器也只有初步规划,对于真实云端应用的特性并没有太透彻的思考,目前的研究成果都是团队在实际研究中不断梳理总结而成的。
一直以来,我们实验室的研究都是以赛灵思 FPGA 为基础。在此次研究中,我们使用赛灵思 Alveo U200 数据中心加速器卡搭建了云端加速器的本地环境。同时,我们也用到赛灵思 Virtex UltraScale+ VU9P 实现 FPGA 虚拟化环境,这是一个阿里云 F3 的实例,我们希望除了本地有一个可比拟的环境,在云端也有一个环境去验证我们的设计。
后续计划
完善整个FPGA虚拟化系统演示
曾书霖:未来我们会继续就 FPGA 虚拟化整个课题,对研究以及论文进行系统层面的拓展,我们的目标是继续发表一篇系统领域的期刊论文。目前,整篇论文的工作还是以相对简单的DNN负载在单个 FPGA 上加速器的性能仿真为主,下一步的系统层面拓展会有一个更加复杂的软件栈,除了底层硬件加速器、软件编译器,还会有操作系统、通信协议和一些虚拟化容器(container)实现宿主机和用户之间的对接。我们的后续工作包括在软件系统层融合主机端和客户端的通信框架,搭建基础的虚拟化操作系统,并针对整个软件栈从系统的角度进行针对复杂的云端 AI 负载开展一些实验性探究,完善整个 FPGA 虚拟化系统的 demo。
另外,我们还会考虑把研究扩展到大规模的、多块 FPGA 的数据中心场景,从单卡设计拓展到多卡设计。可以预见到的是,在未来研究中随着多卡的引入,我们会面临一些崭新的挑战,而我们也也需要站在更宏观的角度对更多情况进行综合考量,这些对我们团队的科研能力是非常好的锻炼。
FPGA 研究
挑战与机遇并存的新课题
曾书霖:我在赛灵思和收购之前的深鉴科技都有过实习经验,这也使我对 FPGA 和 AI、深度学习有了更深入的体验。在赛灵思实习时,我在负责 FPGA 开发的硬件组,组长给我的任务是学习使用赛灵思的 SDAccel/SDx 工具(现已整合进 Vitis),于是我得以接触到针对云端软件的开发工具,这在我后来进行这一研究以及开展实验起到了非常重要的作用,因为研究过程中的很多工作是围绕 SDx 开展的,并且数据中心里面一个很重要部署的软件就是 SDAccel。
在我看来,FPGA 在未来将是一个与 CPU、GPU 同样必不可少的芯片品类,特别在数据中心场景里将扮演重要角色。未来的数据中心将是异构计算为核心的硬件数据中心,在这种场景下,单独依靠每一个硬件都无法实现整个数据中心性能和能效的最大化,我们必须要综合考虑不同的硬件,以虚拟化思想尝试把所有硬件资源最大化利用起来。业界与学术界此前针对 CPU、GPU 的研究已经较为充分,但对于如何把 FPGA 性能与能效最大化以及如何与其他硬件相结合,以实现一个支持智能应用的异构系统,还有很大的空间可以发展,当然同时也是一个颇具挑战性的课题领域。
关于汪玉研究团队

曾书霖于2018年本科毕业于清华大学电子工程系,目前正在清华大学电子工程系攻读博士学位,2017年加入清华大学汪玉教授研究团队。他的研究方向包括深度学习加速器、软硬件协同加速和异构系统虚拟化设计。

清华大学汪玉老师是电子工程系长聘教授,博士生导师,国家优秀青年科学基金获得者,IEEE/ACM高级会员,深鉴科技联合创始人。长期带领团队从事高能效电路与系统的研究工作,包括面向应用域的定制加速器、类脑计算、存内计算等方面的研究。
关于 姚 颂
姚颂现任赛灵思人工智能业务高级总监,负责公司在全球领域的人工智能业务拓展和生态建设。加入赛灵思之前,姚颂为深鉴科技( 2018年7月并入赛灵思公司)联合创始人、首席执行官,带领团队自主研发了高效的深度学习平台,致力于为智能安防与数据中心等行业提供集算法、软件、芯片为一体的人工智能方案。