作者:Giulio Corradi、Víctor Mayoral-Vilches,赛灵思公司
术语「软件定义硬件(Software-defined Hardware)」,往往指将应用映像至FPGA,进而透过软件创建运行时可重配置硬件。软件定义硬件旨在实现特定算法或运算的运行时效率最大化,是使用固定的冯纽曼运算架构的CPU和GPU,或是成本高、同样功能不可变的ASIC的替代产品。因此,针对机器人的软件定义硬件,应被理解成能够透过软件重新程序设计和适配的运行时可重配置机器人硬件。
传统的机器人软件程序设计是在预定义的架构和约束条件下,在给定机器人的CPU中进行功能程序设计。正如上篇文章所述,一旦机器人遇到适配需求,就会导致复杂的系统整合操作。然而如果使用FPGA,构建机器人的行为就是为解决任务的架构程序设计。机器人架构师可以纯粹从软件创建自己的硬件设计,并可以透过各种平台实现。
对于机器人专家来说,有三种与FPGA技术相互影响的途径。首先是芯片级入手(Chip-down)的方法,即将系统单芯片(SoC)整合到客制化设计的PCB中,以满足应用需求。这种方法较适合机器人制造商,是大量和成本优化型批量的选择。第二种方法是采用系统模块(SOM),将预装配电路板插入客制化的承载电路板。SOM可让硬件工程师加快产品开发速度,将他们从运算平台上解放出来,把精力集中在更有价值的创新上。第三种方法是采用已经整合大量周边、完全装配好的电路板。对于高强度的运算而言,可直接插入工作站的完整电路板,为权衡取舍下较佳的考虑。
总括来说,传统的机器人软件程序设计是在预定义的架构和约束条件下,在给定机器人的CPU中进行功能程序设计。而采用自我调整运算后,构建机器人行为则是针对架构的程序设计。
透过ROS 2整合自我调整运算
机器人操作系统(ROS)是机器人应用开发的实际框架。在Open Robotics的维护和指导下,ROS不仅是一种操作系统,也是一种框架。它由构建和管理机器人的不同工具构成,包括调试和可视化实用工具、编排工具、机器人库(如运动规画、导航、定位等),以及促进机器人系统开发的通讯工具。
目前,由于原始版本的ROS文章已被引用8,500次以上,可充分证明其在研究和学术领域获得广泛认可,因此ROS便在这样的环境下诞生。其主要目的是为开展初期研发的用户提供所需的软件工具。在像ROS-I(ROS-Industrial)这样项目的支持下,ROS在业界的热度持续成长。ROS-I是一个开源计划,目的是将ROS软件的先进功能推广到工业应用。由于ROS-I联盟的带动,ROS现已在业界成功部署。日前该联盟已拥有80多家成员,每年在欧洲、美国和亚洲举办会议,广聚数百位机器人专家和知名制造商。后者藉此机会,透过演示介绍他们自己的ROS驱动程序。
随着ROS超越学术层面开始进入工业和其他领域,ROS的局限性也日渐突显,如缺乏嵌入式支持和深度嵌入的原生支持,单机器人软件架构,无实时功能和缺乏安全性等。为了解决这些问题,Open Robotics于2014年开始重新设计ROS,由此ROS 2问世。ROS 2透过将通讯中间件与机器人逻辑分离,突破大部分已知的局限性。具体而言,Open Robotics选择「数据分发服务(DDS)」作为初始通讯中间件,并针对各种DDS解决方案构建适配器,同时对上层暴露DDS特性。尽管如此,ROS核心层仍然保持免受通讯中间件的影响,ROS 2软件架构如图1所示。
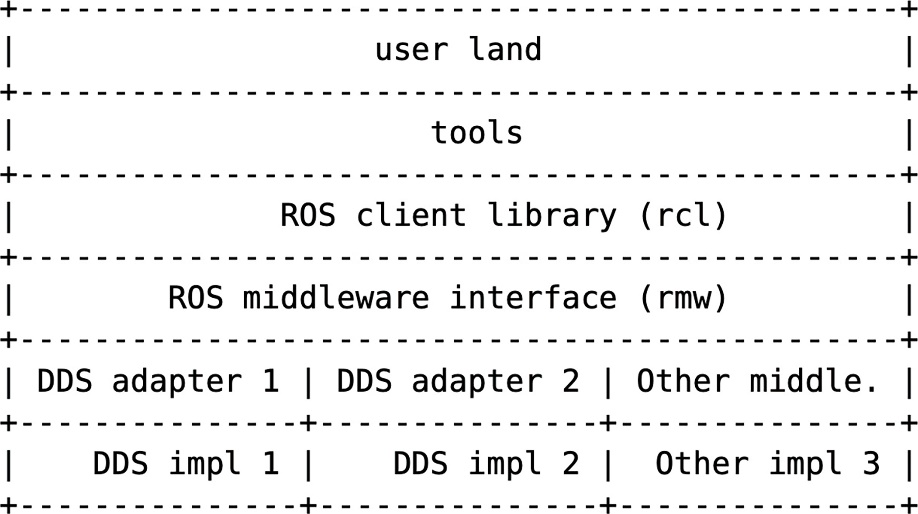
图1 软件架构
上层建立在中间件抽象层(RMW)上,后者负责将ROS抽象层转译成具体的中间件。ROS客户端库(RCL)不会暴露任何具体中间件的实现细节(如DDS)。这样一来,RCL保持免受中间件的影响,且能够轻松扩展到其他需要不同传输方式的应用。
ROS拥有数千名活跃用户,目前已是规模最大的机器人专家群体。ROS因研究而诞生,现已演进发展有十多年的时间,在各种应用领域得到广泛采用,并且还能服务于工业需求。
ROS不仅提供工具、工具库和惯例,而且还拥有不断扩大的机器人专家小区。从概念上讲,ROS在大多数方面围绕着被称为ROS运算图的抽象层。运算图内的每个节点都能开展机器人运算,并透过用底层通讯中间件实现的通用点对点数据总线与其他节点交换信息。数据总线内的信道按主题组织。因此,机器人的总体行为取决于运算图,而运算图可以分布方式实现在一部或多部计算机上。如此就完成了第二次抽象层,也就是将运算图映射到机器人中可用的运算基板,形成ROS数据层图。数据层图代表的是物理分组和连接,用于在运算图中实现建模行为。简单地说,其捕获的是机器人的物理现实,包括通讯总线、机器人组件(包括传感器和/或致动器),以及运算图与现有机器人组件中可用运算基板间的映射。
ROS运算图可以涉及一个或多个机器人,并且本质上是模块化的,能够以分布式或集中式的方式实现。图2所示的是ROS运算图(图2a)和数据层图(图2b)。
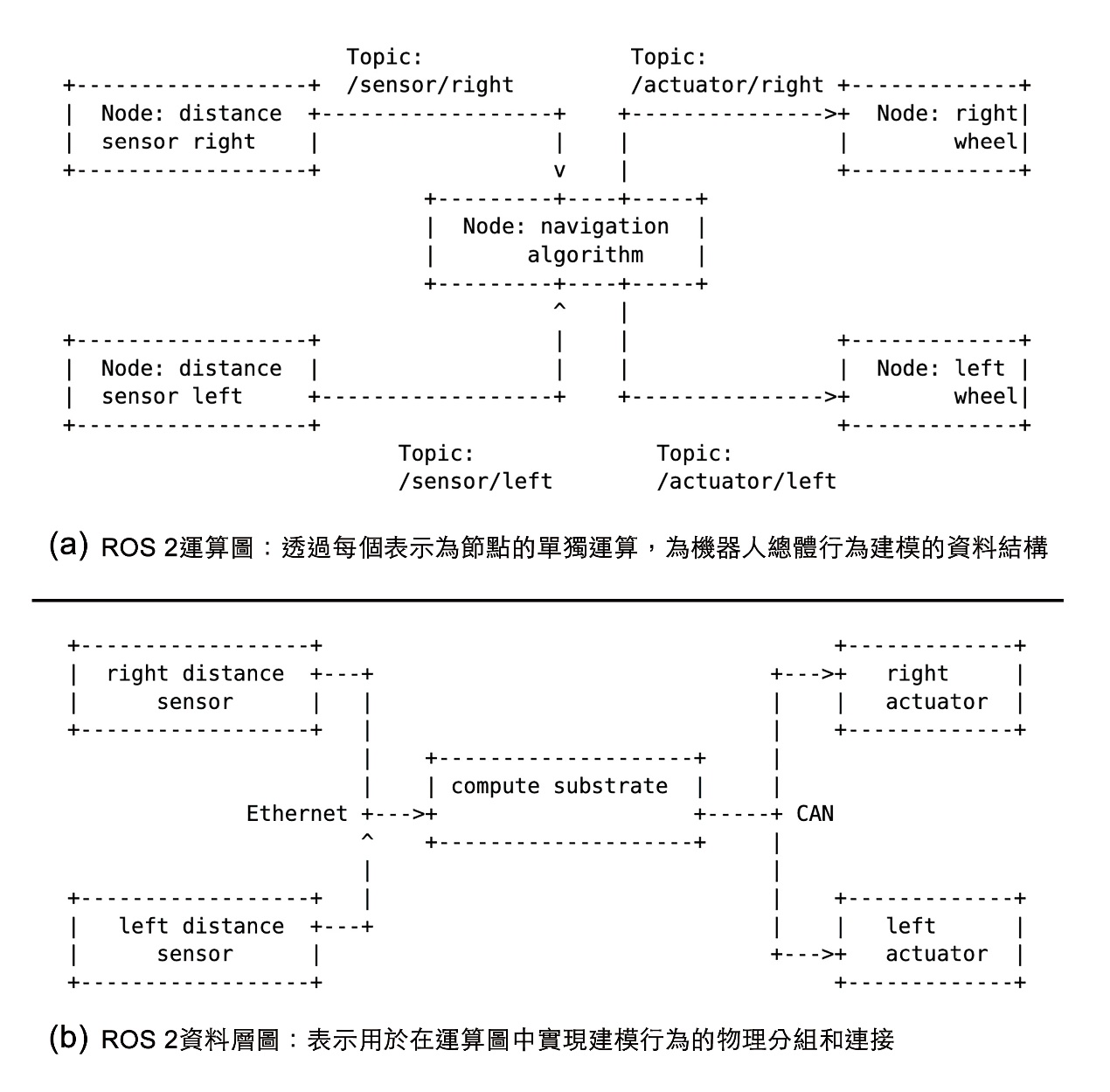
图2 ROS抽象用于具备导航能力的2轮机器人
表1是对一些最重要的ROS概念的总结。

综上所述,ROS运算图是一种为机器人总体行为建模的数据结构,而数据层图捕获的则是机器人组件(用于在运算图中实现建模行为)的物理分组和连接。
自我调整运算平台实现ROS之路
图3所示的是历年来将ROS和ROS 2分别实现在一些自我调整运算平台的既往研究中,较具相关性的成果。
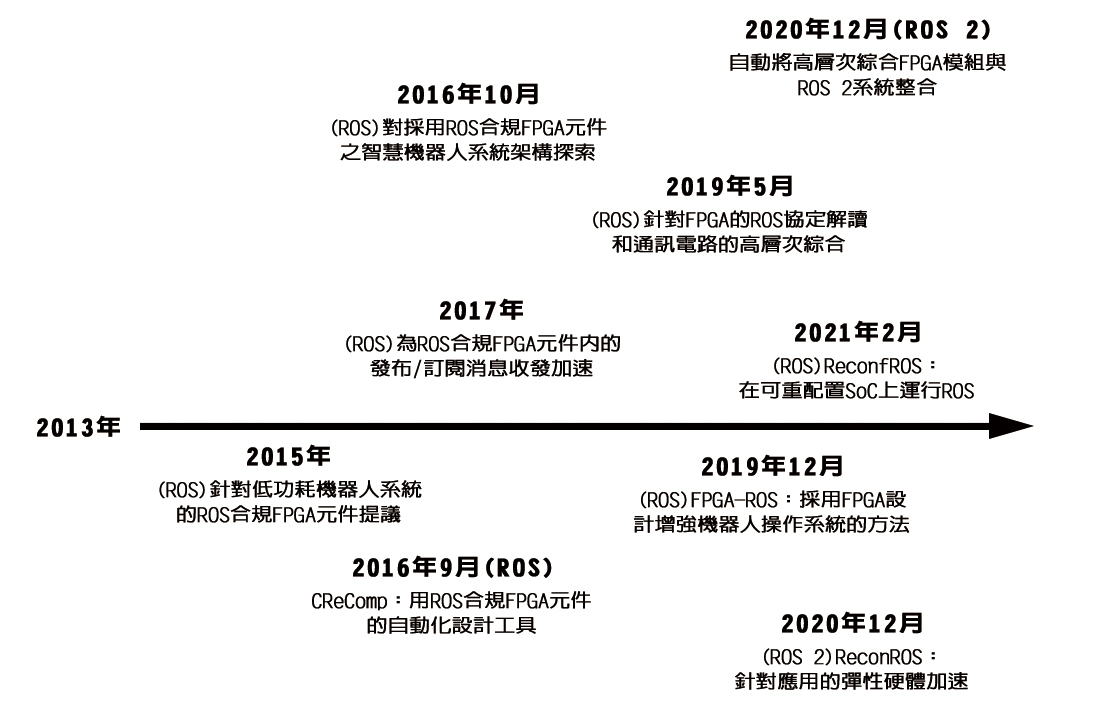
图3 ROS与ROS 2演进变革
从图3也反映出学界对促进自我调整运算发展的兴趣越来越浓厚。从ROS的角度来看,可以将过去的研究分为三类:第一类研究提出叙明机器人专家充分利用硬件加速功能,将ROS运算图的一部分卸除到可程序设计逻辑(FPGA)并进行加速的工具和方法。第二类研究提出加速ROS底层的概念,特别是用网络堆栈优化节点间网络内的相互影响。如根据「Real-time Linux Communications:An Evaluation of the Linux Communication Stack for Real- time Robotic Applications」的描述,网络堆栈是ROS通讯的瓶颈,而「Acceleration of Publish/Subscribe Messaging in ROS-compliant FPGA Component」等研究也对实时分布式系统有参考价值。第三类研究提出用自我调整运算优化ROS运算图。
除了在用户空间层面加速特定应用和ROS库,值得一提的还有在流程间、流程内,乃至网络内的层面加速ROS节点间的相互影响。由于机器人行为建立在ROS节点相互影响的结果上,因此用于此用途的加速器透过从总体上减少ROS和ROS 2运算图数据流,显著影响总延迟。也就是说,在考虑ROS和ROS 2时,必须应用全面的硬件加速视图。这种视图能体现针对流程中、流程内、网络内(含底层)ROS运算图相互影响的优化,以及针对ROS上运行应用的加速。 根据图3列出的既往研究,还可以得出另一个结论。过去的大多数方法主要都是从硬件工程师的视角解决自适应运算与ROS的整合问题,其提出的大多数工具和方法都有一个先决条件,即最终用户必须具备嵌入式流和硬件流的既有经验。这往往意谓着需要熟悉RTL、HDL和HLS等概念,或能熟练使用Vivado设计套件与Vitis统一软件平台等工具。类似地,部署到嵌入式目标也需要用户在一定程度上熟悉Yocto、OpenEmbedded以及相关工具。大多数从事ROS研发的机器人专家不具备这样的能力。要整合自我调整运算,需要采用一种以ROS为中心的方法。硬件和嵌入式流程必须直接整合到ROS生态系统中,提供的体验与机器人专家在其桌面工作站上构建ROS工作空间时的体验相似。在充分利用所有既往研究结果和经验的基础上,以下将提出一种以ROS为中心的架构,用于整合自我调整运算。
新架构以ROS 2在机器人内部整合自我调整运算
图4所示的架构将硬件加速整合到ROS 2中,同时坚持以机器人专家为中心的理念。不要求熟悉非ROS工具(如Vivado或Vitis工具),或熟悉OpenEmbedded与Yocto。此外,该架构构建在开放的标准之上,以C++和OpenCL作为生成加速核心的目标运算语言。透过这种方法,机器人领域的大多数用户都可以受益于硬件加速的功能。该架构使用三大支柱构建:ROS构建系统(ament)、ROS元构建工具(colcon)以及嵌入式韧体(firmware)。 第一个支柱是ament ROS 2构建系统的扩展。ament_vitis透过一系列CMake宏(Macro)和实用工具实现这些扩展,将Vitis工具包含到ROS 2生态系统内。提议的架构是一种适用于几乎任何加速技术的架构,即ament_acceleration抽象层从框架和软件平台(如Vitis工具)抽象层构建系统扩展,为FPGA和GPU提供支持。作为替代加速技术的例子,图4中包含了ament_rocm,展现未来整合ROCm5软件开发平台的潜力,以实现超大规模等级GPU运算。在后台,ament_acceleration的每次专门优化都需要对应的库。例如,ament_vitis依靠Vitis和赛灵思(Xilinx)运行时(XRT)库,后者是一种开源的标准化软件接口,用于简化应用代码和加速核心之间的通讯。Vitis工具和XRT完全对机器人工程师隐藏,不仅简化了加速核心的创建,而且还帮助机器人专家专注于运算图像的改进。透过提供犹如任何其他ROS封装的体验,以这种方式实现简化加速核心创建工作的目标。图5所示的代码列表1展示的是使用ament_vitis ROS封装的示例。宏vitis_acceleration_kernel提供灵活性,允许用户无缝地扩展CMakeLists.txt并选择加速ROS封装的哪些部分。
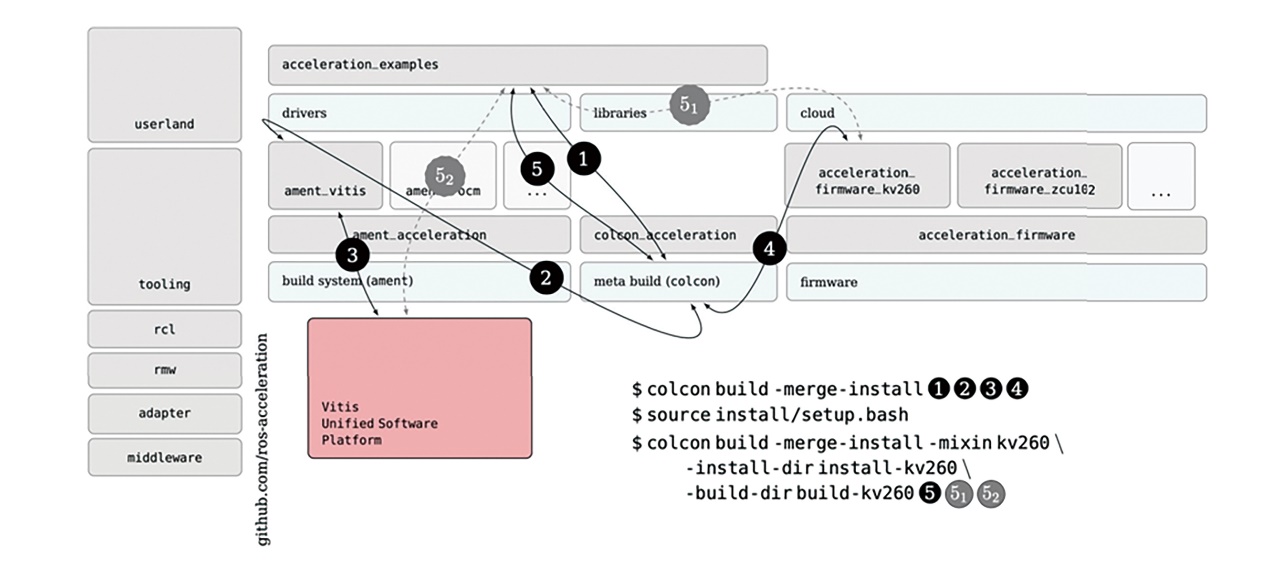
图4 ROS 2硬件加速工作组(HAWG)初始架构
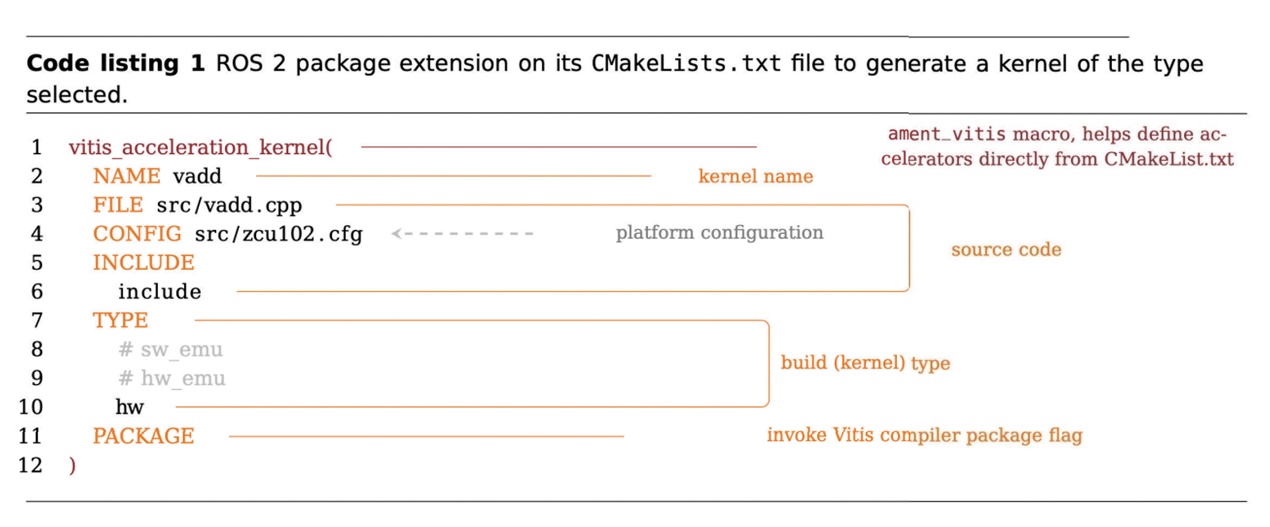
图5 代码列表1
第二个支柱扩展「colcon」ROS元构建工具,以整合硬件加速专用流。
第三个支柱是嵌入式韧体。表达为acceleration_firmware,第三个支柱旨在为硬件加速平台提供韧体专用工件,这样就能针对这些工件编译加速核心,进而简化流程并保持ROS开发流程。提出的架构在构建时特别考虑到各种硬件加速平台,可以支持边缘(嵌入式)组件,以及适用于工作站、数据中心乃至云端硬件加速的PCIe加速器。平台选择透过在ROS工作空间资源(在src/下)中加入特定的acceleration_firmware库来实现。构建过程中的平台选择透过colconmixins来实现。透过这种方式,colcon build-build-base=build-zcu102-install-base=install-zcu102-merge-install-mixinzcu102将为ZCU102硬件平台构建完整的ROS 2工作空间,交叉编译ROS封装,在运行中视情况为ZCU102平台生成核心。所有中间步骤完全实现自动化,而且产生的install-zcu102目录能直接在硬件中使用。
为了容纳中间工件并在嵌入式流程中提供灵活性,acceleration_firmware在ROS 2工作空间中导入新的子文件夹结构,即/acceleration/firmware/路径。
图6是acceleration_examples ROS 2封装构建完成后,该架构的工作方式预演。流程从colcon构建ROS 2工作空间开始(图6,插图编号1)。毋需使用特殊的旗标,只是对应的封装和硬件加速工作组(HAWG)基础设施必须位于工作空间的src目录内。colcon将为开发工作站架构构建每一个封装。这其中包含ament_vitisCmake宏(图6,插图编号1),该宏将一系列CMake扩展部署到产生的本地ROS 2迭加工作空间中。 这些扩展与本地Vitis安装(图6,插图编号3)相连,对ROS 2封包直接提供其功能。换句话说,ROS 2封包能从它们的CMakeLists.txt文件使用这些宏,并且使用硬件加速工具。
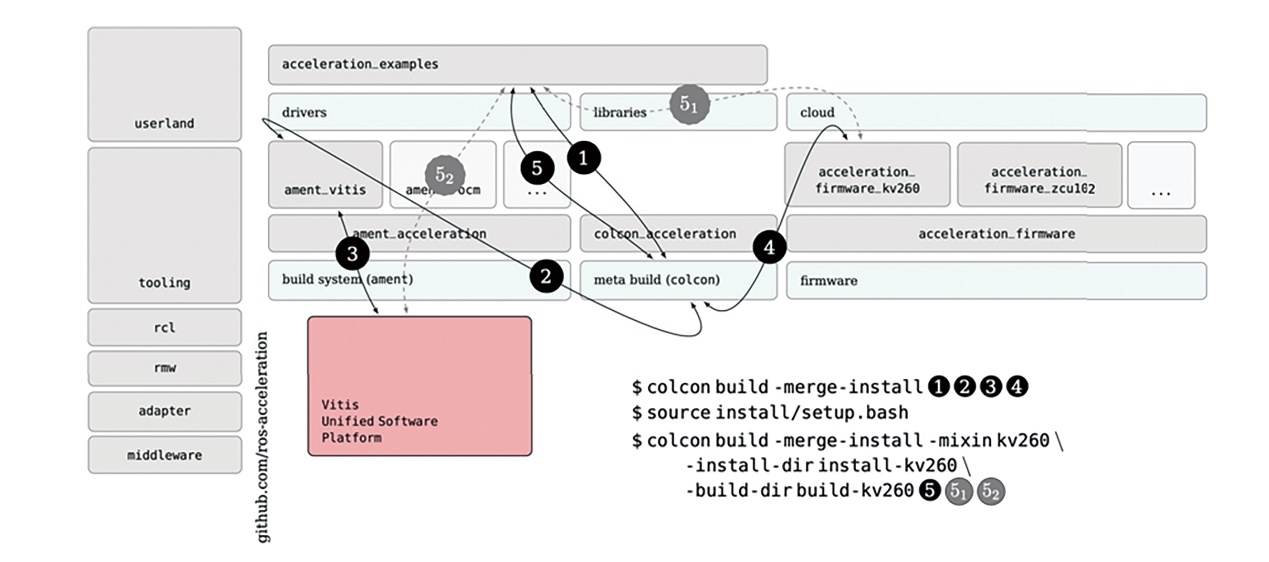
图6 HAWG初始架构内ROS 2封包之间的相互影响走查
韧体封包(如acceleration_firmware_kv260)是该架构的重要组件。切换加速器时,只需以适用于新目标加速器的封包替换这个封包即可。任意一个有效的韧体封包都应包含韧体工件和CMake逻辑,以便在ROS迭加工作空间中正确地为实现硬件加速目的而解封包、部署和配置韧体(图6,插图编号4)。此外,有效的韧体封包应包含根文件系统、根文件系统的sysroot(用于交叉编译)或在构建时自动生成ROS 2 mixins的模板,以简化嵌入式流程和其他部分。 总之,首先调用colcon构建(图6,插图编号3),让ROS 2工作空间为硬件加速做好准备并将档案部署在本地迭加内(图6,插图编号2、3和4)。在此之后,从本地迭加第二次调用带-mixin旗目标colcon构建,将进行交叉编译(图6,插图编号5₁ )并根据需要为目标加速器硬件生成加速器(图6,插图编号5₂)。从这一点开始,colcon_acceleration封包有助于其余流程的进一步自动化。
下列三种不同的电路开发板已经获得基本支持:如赛灵思Zynq UltraScale+ MPSoC ZCU102、ZCU104以及Kria KV260视觉AI入门套件。 在既往研究的启发下,当前研究提出一种以ROS 2为中心的架构,让硬件加速在ROS生态系统中发挥关键作用。这种架构适用于各种平台(瞄准边缘、工作站、数据中心或云端提供支持等),也适用于支持FPGA和GPU的各种技术,并且只需提供对应的专业acceleration_firmware,就能轻松地将其移植到其他电路板。