本文转载自:FPGA的现今未微信公众号
在FPGA的设计中,尤其是在通信领域,经常会遇到hash算法的实现。hash算法在FPGA的设计中,它主要包括2个部分,第一个就是如何选择一个好的hash函数,减少碰撞;第二个就是如何管理hash表。本文不讨论hash算法本身,仅说明hash表的管理。
原理
先对齐本文中要说明的几个概况,如下图所示,hash函数的输入称为key,hash函数的输出,称为hash值,或者index。以上称呼可能不标准,但是不影响对方案的理解即可。

hash算法的实现可以用一个很简单的图来表示,如下图所示,对输入的key做hash运算后,得到index,以index作为地址,把key值存入到其index对应的hash表中。同理,在查询的时候,也是先对key计算hash值,然后查hash表,如果hash表无效,说明没有命中,如果有效,则判断hash表中的key和输入的key是否相等,相等则为命中。
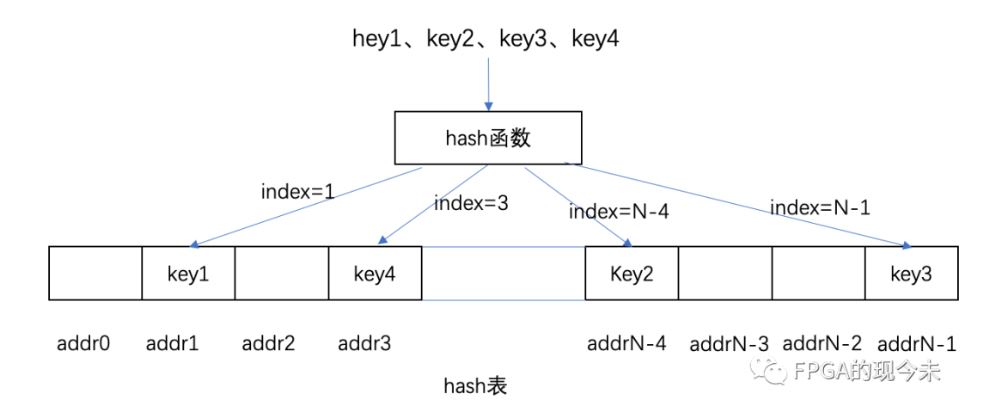
举2个例子简单说明下,假定key5,计算出index = 0,但是add0为空,所以key5没有命中,或者说,hash表中没有key5这个元素。假定key6,计算hash后得到index = 3,hash表addr3中有数据,但是存放在addr3中的数据为key4,不等于key6,所以key6也没有命中。
hash表构建
上图hash表的示意图其实已经说明了一个简单的hash表的构建,在FPGA内部,常用BRAM来存放一个hash表,上图所示hash表的深度为N,每个hash表中存放一个key。假如key的位宽为50个bit,hash后的index位宽为9bit。那么hash表就需要一个64bit*512表项,消耗1个M36K(以xilinx的资源为例)。
但是事情肯定没有这么简单,因为只要有hash的地方就有冲突。那么下一步就是要解决hash冲突的问题。
解决hash冲突最常见的方案就是hash链表,如下图所示,key1、key5、key7具有相同的hash值,可以通过一个链表的形式将他们串联在一起。这种方案在软件是可能是非常好实现的,但是在FPGA里实现可能就比较难了,比如链表的最大深度为多少呢?每个hash桶的链表是单独存放还是所有的存放在一起呢?

我们知道一个好的hash函数,应该是要尽可能地减少冲突的。如果从算法上我们证明了,我们的冲突最多不超过4次,那就有更加简单的方案来实现这个hash表了。
我们把hash表做一个改进,如下图所示,我们每个hash桶中,不再是存放一个key,而是最多存放4个key,也就是不用链表来解决hash冲突问题。
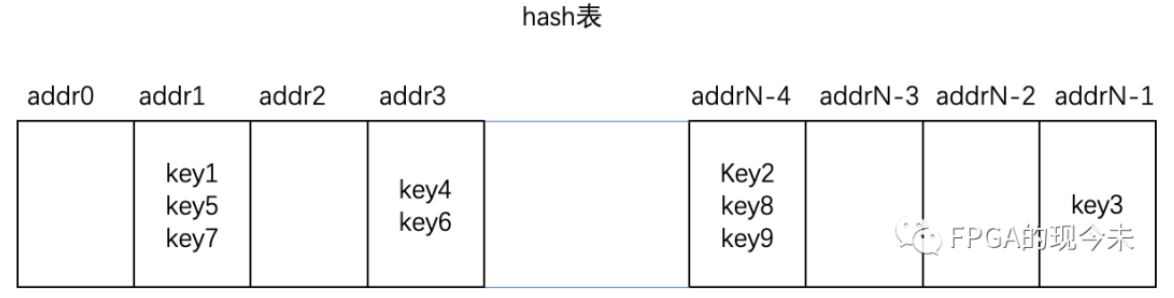
这样做的好处有2个,一个是没有了对链表的处理,比较简单,第二个就是处理速度快,一次读操作就把具有相同hash值的所有key值全部读出来进行比较。那这种方案在FPGA的ram中如何实现呢?还是以key的宽度为50bit,index的位宽为9bit为例。
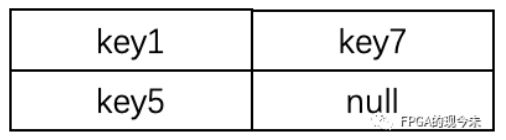
一个桶的内部结果如下图所示,每个key还需要1bit指示是否有效,那么4个key需要51*4 = 204bit,用一个216bit*512的BRAM即可,消耗2.5个M36K。

如果key的位宽非常大,比如是五元组,一共104bit,如果用上述的方案,那就是105*4 = 420bit,那就需要6个M36K来存放。可见,key的位宽越大,消耗的资源就越多。
hash表的优化
如果我的设计,要的就是速度,对资源的消耗不是很关系,那用上述的结构即可,如果我的设计可以牺牲一点点性能,但是需要减少资源的消耗,怎么办呢?
我们可以把hash桶的内部结构修改下,由拼位宽改成拼深度,如下图所示:

分别以50bit和104bit的key为例,对于50bit的key,需要的存储为64bit*512*4,需要4个M36K。对于104bit的key,需要的存储为108bit*512*4,需要6块。看似需要的缓存并没有减少,有的情况下甚至增加了。
如果hash值是8bit了,那情况就不一样了。因为hash值为8bit和9bit的时候,BRAM的深度的增加,并没有带来额外的资源消耗,但是表项的宽度却只有原来的一半,资源也就可以减少一半。比如原来hash表位 288bit*256,需要消耗4个M36K,采用上述的优化方案后,表项变成144*512,只需要消耗2个M36K。
除了上述的对hash桶的改进外,有时候可以同时拼宽度和深度,如下图所示:
总结
hash表的设计,需要兼顾资源和性能问题。主要的考虑点就是充分利用BRAM 的特性来实现资源和性能的平衡。

当然,hash表也可以不放在BRAM中,存放在DDR里,那就演变成另外一个话题,如何高效地读写DDR中的hash表了。