在 FPGA 上部署 5G NR 无线通信:一套完整的 MATLAB 与 Simulink 工作流程
judy 在 周五, 09/03/2021 - 10:01 提交
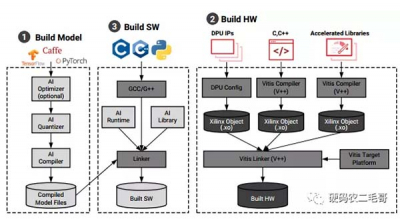
设计创新型无线通信设备需要跨多个学科密切合作。将算法模型部署到 FPGA 硬件可以快速完成原型设计及无线测试,直接从系统级算法自动生成 HDL 代码则可以消除耗时较长的实现和验证步骤。本白皮书通过一个 5G NR 小区搜索设计来说明该过程,介绍将 MATLAB® 算法和 Simulink® 模型直接转换为适用于 FPGA 的 HDL 的工作流。