携手赛灵思,引领极速生态圈,打造金融行业极速IP
judy 在 周二, 10/13/2020 - 10:37 提交
金仕达与全球领先的下一代自适应计算企业赛灵思达成深度合作意向。双方将基于金仕达 FPGA 极速行情系统,围绕交易、策略、风控量化或高频交易等场景全面打造基于 FPGA 的金融方案体系,加速 FPGA 在金融行业的全方位应用,助力金融行业高质量发展。
金仕达与全球领先的下一代自适应计算企业赛灵思达成深度合作意向。双方将基于金仕达 FPGA 极速行情系统,围绕交易、策略、风控量化或高频交易等场景全面打造基于 FPGA 的金融方案体系,加速 FPGA 在金融行业的全方位应用,助力金融行业高质量发展。

上周五,一个爆炸性消息传遍业界:AMD将以300亿美元价格收购FPGA龙头老大Xilinx!媒体们争相转载这个消息收割眼球。赛灵思的股票也应声涨起来,从100美元左右冲到120美元,市值向300亿美元看起。

决策树加速器可加速梯度提升树和随机森林算法的推断进程。它能够与通过 XGBoost、LightGBM、Scikit 学习、H2O.ai 和 H2O 无人驾驶 AI 创建的模块协同工作。该软件允许数据科学家和工程师构建快速、可扩展的高成本效益机器学习基础架构,无需改变机器学习框架的使用
本视频选自AMD 高速互连 创新无限——AMD (超威) PCIe 4 生态&解决方案网络峰会”, 就数字化转型时代AMD (超威) 如何构建PCIe 4 生态,加速HPC、机器学习、虚拟化、数据库、网络、NFV和5G等应用场景数据中心动态工作负载,助力企业不断取得领先。

本手册详细介绍 Vivado工具的功能特色,包括 FPGA 设计的逻辑和时序分析以及工具生成的报告和消息。探讨达成时序收敛的方法,包括审查时钟树和时序约束、设计布局规划以及实现运行时间与设计结果的平衡。

对于使用AXI总线,最开始肯定要了解顶层接口定义,这样才能针对顶层接口进行调用和例化,打开axi_lite_v1_0.v文件,第一段就是顶层的接口定义:
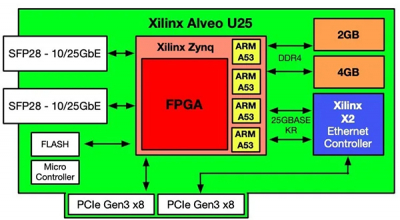
普通 NIC 定位于高效迁移服务器的网络数据包,通常包括不同程度的为优化性能而设计的传统卸载。SmartNIC 整合了多方面的附加计算资源,但是这些架构就像雪花一样各不相同,因此,我们将深入研究规模最大、最受欢迎的供应商所提供的几种方法。

要看到AXI-Lite的源码,我们先要自定义一个AXI-Lite的IP,新建工程之后,选择,菜单栏->Tools->Creat and Package IP

作为FPGA的发明者——赛灵思,手握极具灵活性、高性能的FPGA技术,似乎看别的芯片都有一种嫌弃不够畅快的感觉。当瞄上显示领域时,就会发出来自心底的一问:“一个FPGA就能解决的事,为什么要那么多ASIC/ASSP?”

Fractal(分形图形),是由IBM研究室的数学家曼德布洛特(Benoit.Mandelbrot,1924-2010)提出的,其维度并非整数的几何图形,而是在越来越细微的尺度上不断自我重复,是一项研究不规则性的科学。下面是一个最简单的例子,首先画一条线段,然后把它平分成三段,将中间那一段用一个等边三角形的两条边代替