Vivado 2020.1 开放下载,中文资料随贴奉送
judy 在 周四, 06/18/2020 - 09:28 提交
Vivado 2020.1 新增以下功能:
能够将完整的图像或选定的产品作为 Web 安装程序的一部分
增强的地址映射,用于实时错误高亮显示和交叉探测
Report QoR Suggestions 功能可预测多达 3 种自定义策略,以提升性能
嵌套 DFX 为您的 DFX 解决方案提供了更大的灵活性
基于电源通道的报告
Vivado 2020.1 新增以下功能:
能够将完整的图像或选定的产品作为 Web 安装程序的一部分
增强的地址映射,用于实时错误高亮显示和交叉探测
Report QoR Suggestions 功能可预测多达 3 种自定义策略,以提升性能
嵌套 DFX 为您的 DFX 解决方案提供了更大的灵活性
基于电源通道的报告

随着互联网与大数据技术快速发展,全球进入了一个信息数据爆炸的时间节点,而这也对目前现有的数据中心系统提出了更高的要求。为了适应全新的工作负载与技术需求,现代数据中心亟需进行改变。Alveo 系列数据中心加速器卡的横空出世,为数据中心注入了全新的活力。

本文展示了通过使用 Design Gateway 的 NVMeG3-IP 内核在 Xilinx 的 ZCU102 评估套件上实现 NVMe 固态硬盘 (SSD) 接口的解决方案,该方案可实现惊人的快速性能:写入速度达 2,319 MB/s,读取速度达 3,347 MB/s。

赛灵思今天宣布推出两款易于扩展、超高密度视频转码专用的实时计算视频实时转码一体机。基于赛灵思新型的实时服务器( RT Server )参考架构,两大全新一体机将双管齐下,助力当今服务提供商以每通道最低成本提供视频质量和比特率优化的多种类型应用

AXI4 从站接口将 AXI4 事务映射到 UI,以向内存控制器提供行业标准总线协议接口。UI 块向用户提供 FPGA 逻辑块。它通过呈现平面地址空间和缓冲读写数据来提供对本机接口的简单替代。
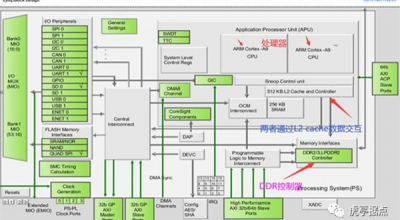
在ZYNQ的PS侧存在Cache,CPU与DDR之间通过Cache进行交互,数据暂存在Data cache中,在处理器对DDR进行写数据操作时,如果不将数据通过Cache送入DDR,DDR中的数据不会变化。在进行DMA操作时,如果没有对Cache进行适当的操作,可能导致以下两种错误

现在,企业和专业用户越来越意识到从物理和虚拟世界收集到的大量数据蕴含的价值。随着数据量继续呈指数级增长,对数据分析的需求也将以类似的速度增长。为此,数据中心必须加速转型,以达到增加网络带宽,优化人工智能等工作负载的目的

本文简要介绍了 ToF 传感器的工作方式。然后,本文将介绍 Digilent 的 Pmod ToF 板,并说明如何将其与 Digilent 的 Zybo Z7-20 开发板结合使用,以评估 ToF 技术并在自己的设计中快速部署光学距离感测。

本文演示了使用Vivado设计套件和Xilinx软件开发套件构建基于Zynq UltraScale + MPSoC处理器的嵌入式设计。提供有效的嵌入式系统设计的动手教程。

“以新发展理念为引领,以技术创新为驱动,以信息网络为基础,面向高质量发展需要,提供数字转型、智能升级、融合创新等服务的基础设施体系。”这便是的近来备受关注的新基建。按下快进键的新基建,也在推动着智慧安防、智慧交通和智慧城市等领域的快速发展。