PowerAI Vision - 面向图像与视频的 Auto AI解决方案
judy 在 周五, 09/25/2020 - 09:33 提交
PowerAI Vision 使具有深度学习的计算机视觉更易为企业用户所用。现在,您可在 Xilinx® Alveo™ FPGA 上部署 POwerAI Vision 模型,并了解如何将 Vitis™ 库集成至面向 Vision AI 任务的整个工作流程中。
深度学习是一种基于人工神经网络的机器学习方法,它通过多层神经网络对数据进行建模和学习,从而使计算机能够自动从数据中提取特征并进行预测。深度学习在图像处理、语音识别、自然语言处理等领域取得了显著的突破,特别是在大数据和强大计算能力的支持下,深度学习已成为解决复杂问题的主要技术。
PowerAI Vision 使具有深度学习的计算机视觉更易为企业用户所用。现在,您可在 Xilinx® Alveo™ FPGA 上部署 POwerAI Vision 模型,并了解如何将 Vitis™ 库集成至面向 Vision AI 任务的整个工作流程中。

米尔科技的FZ3是与百度紧密合作推出的一款基于Xilinx Zynq Ultrascale CZU3EG芯片打造的深度学习计算卡,芯片内部集成了4核ARM A53处理器+GPU+FPGA的架构,具有多核心处理能力、FPGA可编程能能力以及视频流硬件解码能力等特点。

本次演讲,就目前比较火热的视觉传感器和激光雷达来进行阐述和讨论。还将介绍赛灵思汽车级器件的产品路线、传感器的发展趋势、神经网络在视觉中的加速等。另外,赛灵思在前视系统、环视系统、激光雷达中的应用与解决方案也将一一与您展示。

赛灵思全球分销合作伙伴——全球领先的技术解决方案提供商安富利公司亚洲宣布,其和 AI 软件领域的创新企业 Mipsology 达成协议,将向其亚太区客户推广和销售 Mipsology 的独特的 FPGA 深度学习推理加速软件 —— Zebra 软件平台

深度学习 AI 应用是解锁生产力新时代的关键,人类的创造力能够通过机器得到提高与增强。我们致力于将大量培训数据和海量数学运算用于全面训练每个神经网络。训练可使用大规模批处理功能离线进行,历时数天。经过训练的网络要投入部署,那就面临严格得多的时限要求。

本文首先介绍深度学习中的YOLOv2-Tiny目标检测算法,然后设计对应的硬件加速器,并且就加速器中各模块的处理时延进行简单建模,给出卷积模块的详细设计,最后,在Xilinx公司的Zedboard开发板上进行评估。
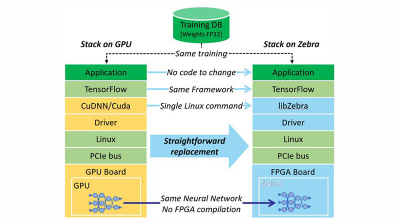
Zebra 可消除深度学习推断中具有挑战性的编程及 FPGA 任务。Zebra 可轻松部署和适应广泛的神经网络及框架。

Zebra 可消除深度学习推断中具有挑战性的编程及 FPGA 任务。Zebra 可轻松部署和适应广泛的神经网络及框架。

使用 Xilinx 深度学习处理器(DPU)IP 构建自定义系统,使用面向 Xilinx SoC 的 DNNDK 优化经过训练的推断模型。

随着AI的广泛应用,深度学习已成为当前AI研究和运用的主流方式。面对海量数据的并行运算,AI对于算力的要求不断提升,对硬件的运算速度及功耗提出了更高的要求。目前,除通用CPU外,作为硬件加速的GPU、NPU、FPGA等一些芯片处理器在深度学习的不同应用中发挥着各自的优势,但孰优孰劣?