卷积神经网络能用 INT4 为啥要用 INT8 ?- 最新白皮书下载
judy 在 周三, 08/12/2020 - 09:58 提交
对于 AI 推断,在提供与浮点媲美的精度的同时,int8 的性能优于浮点。然而在资源有限的前提下,int8 不能满足性能要求,int4 优化是解决之道。通过 int4 优化,与现有的 int8 解决方案相比,赛灵思在实际硬件上可实现高达 77% 的性能提升。
为智能硬件开发者、创客提供有关英特尔嵌入式处理器的相关文档、软件包、开源文档资料
对于 AI 推断,在提供与浮点媲美的精度的同时,int8 的性能优于浮点。然而在资源有限的前提下,int8 不能满足性能要求,int4 优化是解决之道。通过 int4 优化,与现有的 int8 解决方案相比,赛灵思在实际硬件上可实现高达 77% 的性能提升。

本文描述如何从 Vivado® 高层次综合移植到 Vitis™ 高层次综合。

本文介绍Zynq®UltraScale +™MPSoC中与安全相关的eFUSE的编程,以设置ZCU102板的安全启动。

赛灵思 Kintex® UltraScale+™ FPGA 支持 -3、-2 和 -1 速度等级,其中 -3E 器件性能最高。-2LE 器件和 -1LI 器件可以 0.85V 或 0.72V 的VCCINT 电压工作,并提供更低的最大静态功耗。

FPGA 器件凭借强大的功能、灵活性和即时可用性形成极具吸引力的业务驱动力,掀起了一场广泛采用 FPGA 来实现系统 PCB 设计的浪潮。很显然,FPGA 器件的上市时间优势和容量/性能特性已兑现其产品承诺,成为更多资本资源密集型定制 IC/ASIC 解决方案的可行替代方案

Zynq® UltraScale+™ RFSoC ZCU208 评估套件是面向开箱即用评估及前沿应用开发的理想 RF 测试平台。该套件包含 UltraScale+ RFSoC ZU48DR,其集成 8 个 14 位 5GSPS ADC、8 个 14 位 10GSPS DAC 以及 8 个软决策前向纠错 (SD-FEC) 内核,专为快速启动 RF 类应用而设计。

Megh 开发了视频分析解决方案 (VAS) 来解决零售供应链中的库存损耗问题。该解决方案主要针对不同的使用案例,包括零售场所的防欺诈、制造中的库存跟踪,以及物理安全的视频监控等。 该解决方案在 Megh 的实时分析平台上运行,该平台可将整个实时分析流水线映射到集成在用户应用中的多个联网 FPGA 中
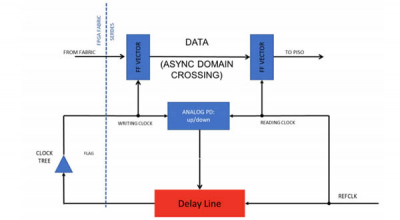
在Xilinx平台上,可实现的PTP精度受所用架构而不是硬件的限制。这是一种范式转换,它使开发人员可以在仍使用标准硬件平台的情况下达到其应用程序所寻找的精度。
INT8提供了比浮点数更好的性能,精度可与AI推论相比。但是,如果INT8在有限的资源下无法满足所需的性能,则INT4优化就是答案。通过INT4优化,与当前的INT8解决方案相比,Xilinx可以在实际硬件上实现高达77%的性能提升。

恒扬数据基于FPGA的数据中心LoadBalancer加速解决方案通过提供高性能网关加速服务,可以帮助客户数倍提升基于软件的网络LoadBalance性能,快速缓解数据流量激增带来的性能压力,并大幅削减扩容带来的费用开支。