重要消息请查收-赛灵思全球自适应计算挑战赛拍了拍你
judy 在 周四, 11/26/2020 - 10:09 提交
亲爱的开发者朋友,首先感谢您对首届赛灵思全球自适应计算挑战赛的信任与支持!为了帮助大家顺利完成提交,我们在这里再次为大家明确相关要求和提交指引。
亲爱的开发者朋友,首先感谢您对首届赛灵思全球自适应计算挑战赛的信任与支持!为了帮助大家顺利完成提交,我们在这里再次为大家明确相关要求和提交指引。
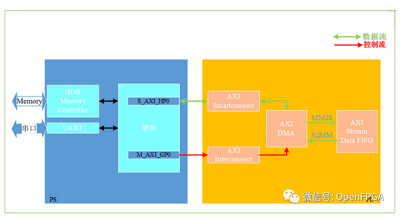
增加一个AXIDMA章节,这部分内容是很多例程的基础,难度不大但是也不小,需要彻底理解整个运行机制。

在VCU TRD 2019.1的Linux里,使用devemem读写内存,得到错误“devmem: mmap: Operation not permitted”。

过去三十年间,基于服务器的计算历经多次飞跃式发展。上世纪 90 年代,业界从单插槽独立服务器发展到服务器集群。紧接着在千禧年,产业首次看到双插槽服务器,再后来,多核处理器也问世了。进入下一个十年,GPU 的用途远远超出了处理图形的范畴,我们见证了基于 FPGA 的加速器卡的兴起。

自动驾驶技术是汽车产业与高性能计算芯片、人工智能、物联网等新一代信息技术深度结合的产物,也是未来汽车行业发展的“大势所趋”。成立于 2018 年的宏景智驾便是这个赛道的探险者之一,其软硬一体自动驾驶计算平台是目前中国市场上少有支持高阶自动驾驶的通用型平台解决方案。

2020 年 12 月 8 日 – 9 日,由赛灵思举办的“Xilinx Adapt China:5G”虚拟研讨会上,业界专家从多种角度深度挖掘 5G 技术特点;详述 5G 部署的复杂性;同时对于 5G 的下一阶段构建和实现,提供最佳解决之道。

在上周举办的 2020 世界超算大会(SC20)上,赛灵思通过现场演示,展示了赛灵思 Alveo 加速器卡与 AMD ROCm™ 开放软件平台的集成。该技术预演基于 AMD 高性能计算技术领域的领先地位,特别运用了用户模式队列和共享虚拟存储器,在 Alveo 加速器上提供直接、低时延的工作分派。

本用户指南介绍了UltraScale架构的PCB设计和引脚规划资源。

更换PetaLinux工程的HDF/XSA文件后,PetaLinux工程编译出现FSBL do_configureh错误。使用命令“petalinux-build -x mrproper -f ”,彻底清除工程,再编译工程,不再有问题。

由于网络配置的复杂性,大多数安全和网络监视设备都会收到大量重复数据包。部署在 Alveo 加速卡上的 Accolade FPGA IP 将在所有重复的数据包到达主机应用程序之前快速有效地消除它们。利用此功能,可以回收大量浪费的 CPU 周期并将其用于更高价值的处理。