Altera 推出低于 100 美元的 Agilex 3 AI FPGA,助力边缘 AI 发展
judy 在 周五, 03/14/2025 - 15:12 提交
近日,Altera 宣布正式量产面向嵌入式市场的 Agilex 3 系列 AI FPGA,其最小型号售价低于 100 美元
近日,Altera 宣布正式量产面向嵌入式市场的 Agilex 3 系列 AI FPGA,其最小型号售价低于 100 美元

下午有个朋友问我,现在AI发展这么快,怎么没听过FPGA有什么动静,难道FPGA就真的搭不上AI这趟列车了吗?

今天,随着Altera CEO Sandra Rivera宣布一系列重磅新品与技术进展,标志着这家独立运营的FPGA巨头正式迈入“Altera 2.0”时代
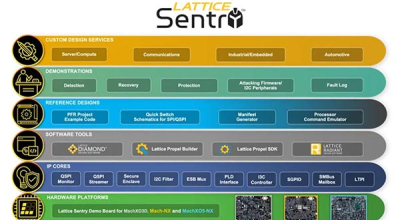
在AI技术蓬勃发展的当下,数据安全问题成为了高悬于行业之上的达摩克利斯之剑。AI模型的训练与应用高度依赖海量数据

本文探讨了垂直电源的优势和应用,重点介绍了 TDK 的 μPOL,以及它如何解决下一代AI和边缘应用所面临的电源挑战。

FPGA AI 套件软件 2024.3 版全新发布,其提供诸多增强功能,旨在改善开发人员的开发体验。为帮助开发人员应对在实际应用中面临的挑战

基于TSMC 16nm FinFET工艺的“下一代小型FPGA”Nexus™ 2平台,在多个关键性能指标上实现了对竞品的超越

协作提高 5G 和 6G 网络的效率并降低成本,使用基于 AI 的自编码器来压缩通道状态信息数据

网络边缘人工智能——即在边缘设备端部署AI模型进行本地化算法处理,而非依赖云端等集中式计算平台——已成为人工智能领域发展最快的方向之一

为提高网络弹性,系统设计人员可将FPGA集成到数据溯源系统中。与固定功能的处理器不同,FPGA作为真正灵活、可重新编程的硬件,能够进行并行处理和实时安全操作